September 2021
tl;dr: Replace MiMo-style (multiple-in-multiple-out) FPN with SiSo (single-in-single-out) neck to build fast and accurate object detector.
This paper delves deep into the success of FPN and proposes that only one feature level can achieve same level of performance.
The success of FPN are due to two factors: 1) multi-level fusion and 2) divide and conquer of label assignment. The paper demonstrates that SiMo structure can also achieve quite good performance, thus we can conclude that
- C5 level feature (32x downsample) carries sufficient context for detecting objects on various scales
- multi-scale feature fusion is far less critical than divide-and-conquer.
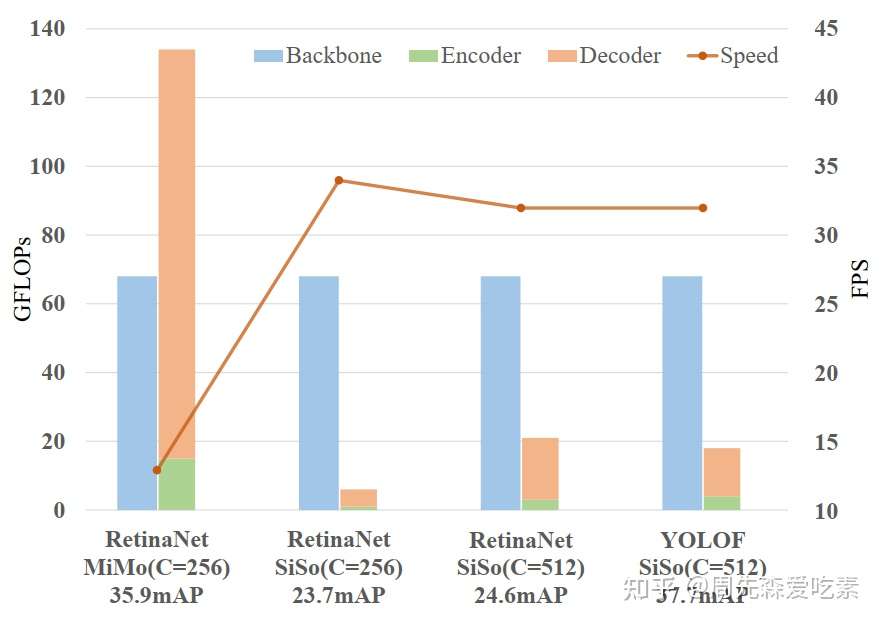
The paper still builds on RetinaNet and can achieve better performance with 57% reduction in FLOPS.
Both ATSS and YOLOF deal with topk anchors. ATSS focuses on dynamically adjusting the threshold to balance the pos/neg anchors based on topk anchors. YOLOF focuses on having balanced pos/neg samples, by ignoring pos samples beyond topk.
- Past work using only one level feature
- MiMo style FPN introduces tons of FLOPS in the decoder. Detecting objects on high-res features maps is expensive.
- However, a simple SiSo neck on C5 does not work well. We have to use Dilated Encoder and Uniform Matching during training. (Uniform matching is more important).
- Dilated Encoder
- C5 features' receptive field can only cover a limited range
- After added in dilated encoder, the receptive field grew bigger
- Skip connection is used to merge the features from the above and cover the engire range.
- Uniform Matching
- topk nearest anchor as positive anchors for each GT. This is similar to ATSS.
- Uniform matching ignores large IoU (>0.7) negative anchors and small IoU (<0.15) positive anchors.
- In RetinaNet, IoU Matching is used to define pos/neg anchors. [0.5, \inf) is defined as positive, [0.4, 0.5) is ignored, [0, 0.4] is defined negative.
- Hungarian matching in DETR can be viewed as top-1 matching.
- Code walk-through in MMDetection
- link on github
- YOLOF is designed to work with anchor-based detectors, but this approach can perhaps help with anchor-free detector design as well. The paper also notes that the predefined anchors may leave some GT bbox not having any high-quality anchor boxes.