[MAP543 Database Management] Final project
Authors
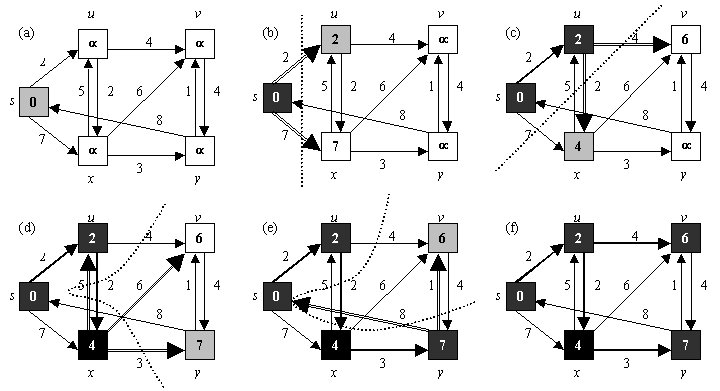
The Dijkstra algorithm is an algorithm that enables to find the shortest/lowest-cost path between two nodes in a graph. In its more common variant, it allows to compute a shortest path tree, i.e. the shortest paths to a source node for each node of the graph. Distance can be considered as the number of hops between nodes or as the sum of the weights/costs of the edges between nodes. It is a restricted application of the best-first search algorithm.
The idea of the algorithm is to iteratively compute each graph node’s distance to the source node, and stop when all nodes have been visited. At each iteration, starting from the source node, each children distance to the selected node is updated with (parent distance + parent-child distance). The node selection is done according to the lowest distance to the previously selected node.
- twitter-formatted.txt : formatted Twitter graph data from the SNAP Project
Generated graph data where nodes may not have outgoing vertices
- shallow-weighted-graph-1000.txt
- shallow-weighted-graph-10000.txt
- shallow-weighted-graph-100000.txt
Generated complete graph data
- weighted-graph-1000.txt
- weighted-graph-10000.txt
- weighted-graph-100000.txt
cd mapreduce
cat my-preprocessed-graph.txt | ./mapper.py | sort -k1n | ./reducer.py > step1.txt
./launch_local.sh <my-graph-file> [-v]
It performs unlimited iterations. Convergence is detected if the sum of distances between all nodes and the source node stops decreasing in iteration n+1
- Input folder : input/
- Contains input graph or the reducer output of the last iteration
- Output folder : output/
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-D mapreduce.job.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-D mapreduce.partition.keycomparator.options=-n \
-input /user/hadoop/input -output /user/hadoop/output \
-file mapreduce/mapper.py -mapper mapreduce/mapper.py \
-file mapreduce/reducer.py -reducer mapreduce/reducer.py
./launch_hadoop.sh <hdfs-input-path> <hdfs-output-path> <local-mapper-path> <local-reducer-path> [nb_iterations]