The project has four main components:
- Scrapy crawler to parse websites for data like posts and comments
- NLTK processing pipeline to extract nouns and adjectives using POS (Part Of Speech) tagger
- Aggregation in Python using Pandas to generate word frequencies and word co-occurences
- D3 force simulations to vizualize the co-occurences
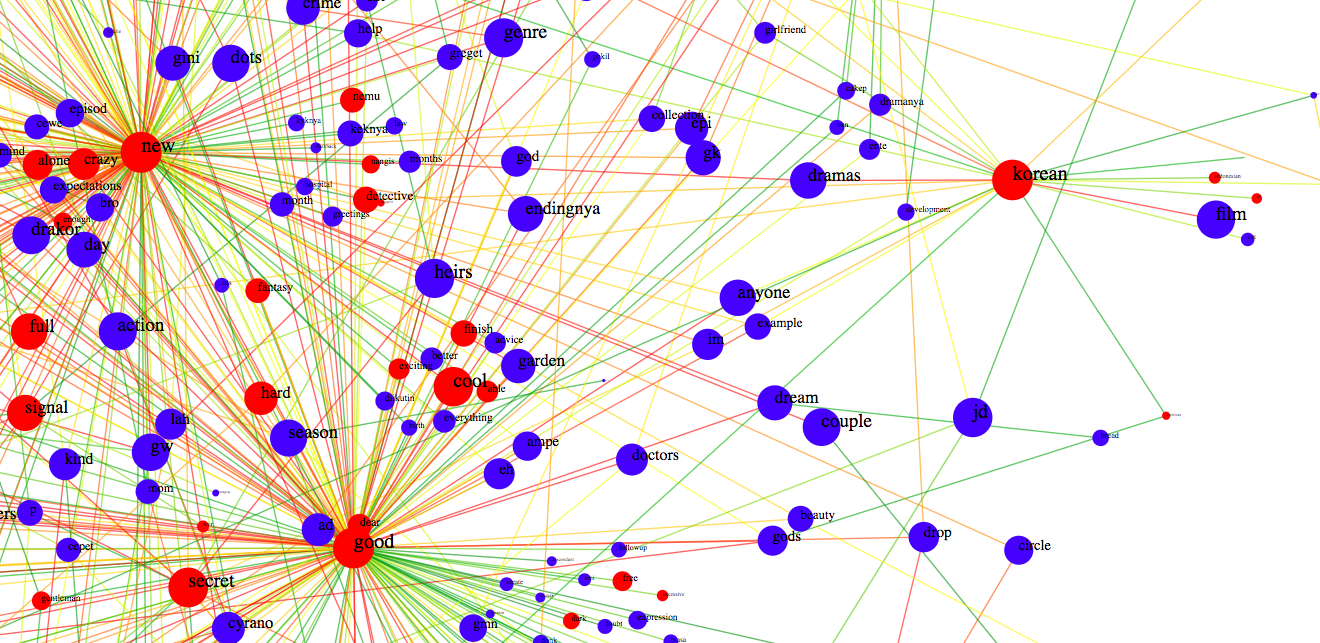
The nodes are colored according to part of speech category, their sizes according to the occurrence frequencies. The links between nodes are gradient coloured according to the co-occurrence frequencies.
With this information, you can figure out what topics are being discussed in a website and what are the common context in which the topics are being discussed and also the sentiment surrounding it.