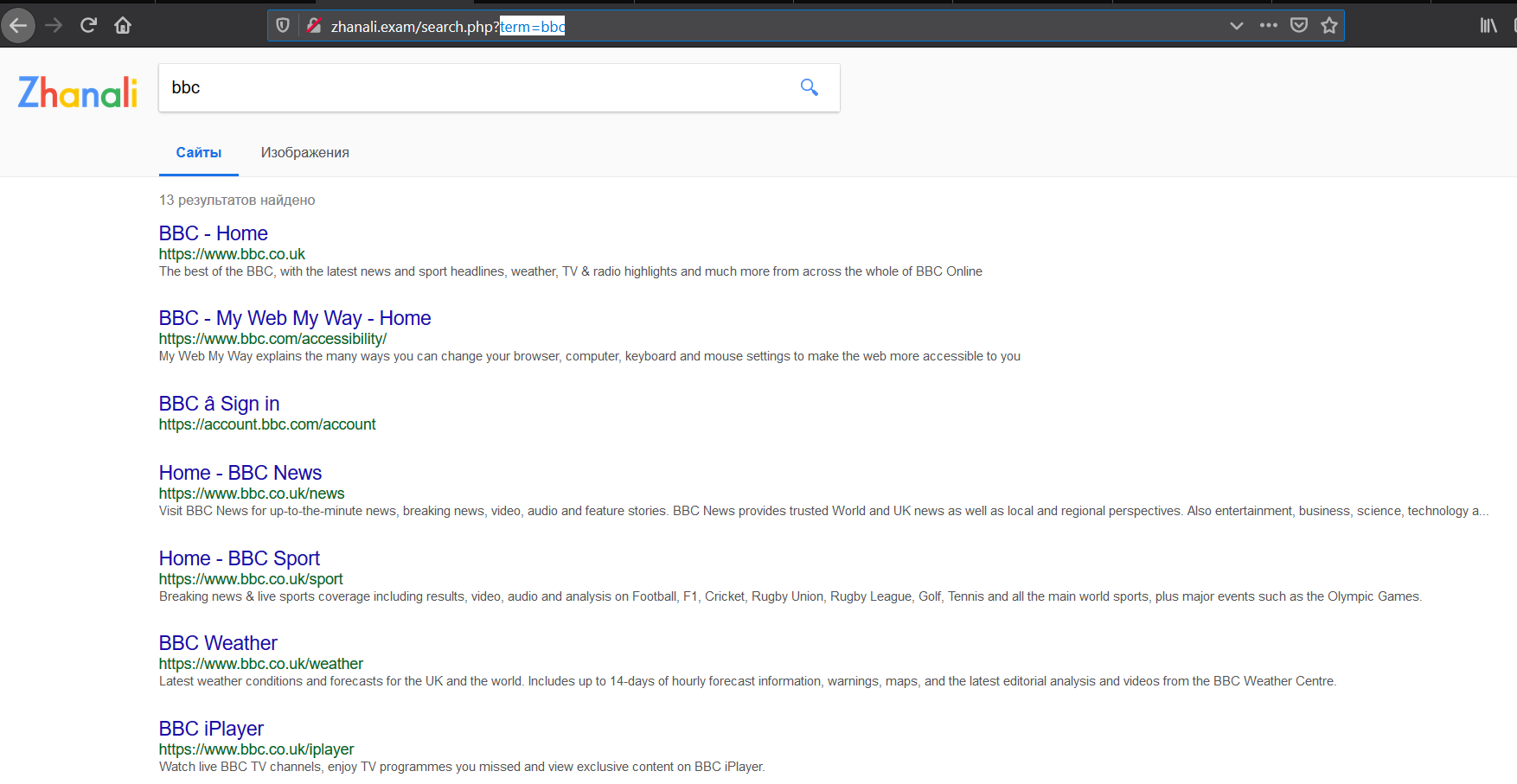
Here you can click on "search". By clicking on the button, the form redirects the user to search.php, where there will be a querry to the database that will display all available sites/images.

The objective of the project is to create a search engine with the following functionality:
- Search the sites for keywords;
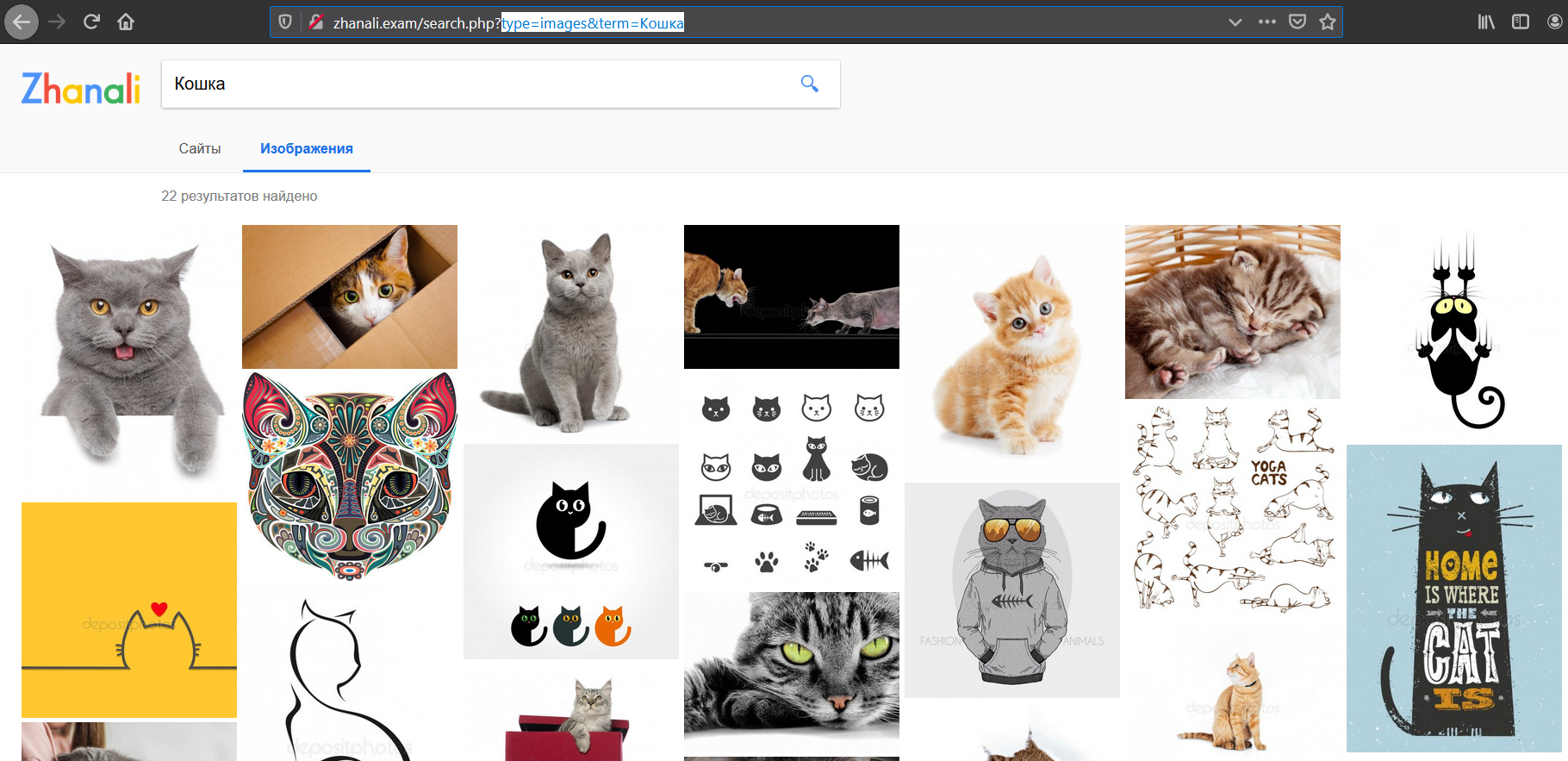
- Search images by keywords;
- Implementation of the pagination system;
- Preview the image when you click on it;
- Updating the database of sites and images.
The website fot creating logos: festisite
Important: display_:_ flex, Google Inspector, DomDocument.
The database consists of two tables:

The "sites" table contains such columns as:” id“,” url“,” title“,” description“,” keywords“,”clicks". It stores links to the site, the site table of contents, site description, keywords, and the number of mouse clicks on the link to determine the relevance of the website, which will help the service display frequently visited sites on the first page.

The database consists of two tables. Table "Images" stores:
- Reference to the website;
- Link on the picture;
- Description of the picture;
- Picture name;
- Number of clicks on the image;
- Is the link to the picture "broken" (0 or 1 parameter).

The mysqli_query(), mysqli_real_query (), and mysqli_multi_query () functions are responsible for executing queries. The mysql_query () function is most often used, since it performs two tasks at once: it executes a request and buffers the result of this request on the client (if there is one). Calling mysql_query() is identical to calling mysqli_real_query() and mysql_store_result () sequentially.
The code below assigns the configuration, that is, it determines where the database is located, logs in as "root", and displays an error message if an exception occurs, as well as assigns additional attributes.
try {
$con = new PDO("mysql:dbname=google;host=localhost", "root", "");
$con->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_WARNING);
}
catch(PDOExeption $e) {
echo "Не удалось подключиться к Базе Данных " . $e->getMessage();
}
Now that we have a database, we need to perform various manipulations with this database. For example:
Sites search:
<?php
if(isset($_POST["linkId"])) {
$query = $con->prepare("UPDATE sites SET clicks = clicks + 1 WHERE id=:id");
$query->bindParam(":id", $_POST["linkId"]);
$query->execute();
}
else {
echo "Не полученно ссылок";
}
?>
or Images search:
<?php
include("../config.php");
if(isset($_POST["imageUrl"])) {
$query = $con->prepare("UPDATE images SET clicks = clicks + 1 WHERE imageUrl=:imageUrl");
$query->bindParam(":imageUrl", $_POST["imageUrl"]);
$query->execute();
}
else {
echo "No image URL passed to page";
}
?>
Every time a user clicks on a link or opens an image, the database needs to update the value of clicks, so that the next time this result is displayed higher in the list of sites. This happens because the program sorts the results by the number of clicks on the link or clicks on the image.
DomDocumentParser.php – responsible for connecting to the site and downloading its HTML code.
<?php
class DomDocumentParser {
private $doc;
public function __construct($url) {
//header
$options = array(
'http'=>array('method'=>"GET",
'header'=>
"Accept-Language: ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3\r\n".
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0\r\n")
);
$context = stream_context_create($options);
// $ch = curl_init();
// curl_setopt($ch, CURLOPT_URL,$url);
// curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);//для возврата результата в виде строки, вместо прямого вывода в браузер
// $returned = curl_exec($ch);
$this->doc = new DomDocument();
@$this->doc->loadHTML(file_get_contents($url, false, $context));
// curl_close ($ch);
}
// Search link HTML-atrubure "a" on the downloadrd HTML-page
public function getlinks() {
return $this->doc->getElementsByTagName("a");
}
// Search title HTML-atrubure "title"
public function getTitleTags() {
return $this->doc->getElementsByTagName("title");
}
// Search metas HTML-atrubure "meta"
public function getMetaTags() {
return $this->doc->getElementsByTagName("meta");
}
// Search image HTML-atrubure "img"
public function getImages() {
return $this->doc->getElementsByTagName("img");
}
}
?>
ImageResultsProvider.php – responsible for querying and displaying all images from the Database.
SiteResultsProvider.php – responsible for querying and removing all sites from the Database.
Crawl.php – responsible for checking whether this link already exists in the database, inserts images and sites, creates links, and gets detailed information about images and sites from the database.
The number of sites displayed at the same time is 20, and the number of images is 30. The maximum number of pages that the search engine shows at the same time is 10.
<?php
$pagesToShow = 10;
$numPages = ceil($numResults / $pageSize);
$pagesLeft = min($pagesToShow, $numPages);
$currentPage = $page - floor($pagesToShow / 2);
if ($currentPage < 1) {
$currentPage = 1;
}
if ($currentPage + $pagesLeft > $numPages + 1) {
$currentPage = $numPages + 1 - $pagesLeft;
}
while ($pagesLeft != 0 && $currentPage <= $numPages) {
if ($currentPage == $page) {
echo "<div class='pageNumberContainer'>
<img src='assets/images/a_red.png'>
<span class='pageNumber'>$currentPage</span>
</div>";
} else {
echo "<div class='pageNumberContainer'>
<a href='search.php?term=$term&type=$type&page=$currentPage'>
<img src='assets/images/a.png'>
<span class='pageNumber'>$currentPage</span>
</a>
</div>";
}
$currentPage++;
$pagesLeft--;
}
?>

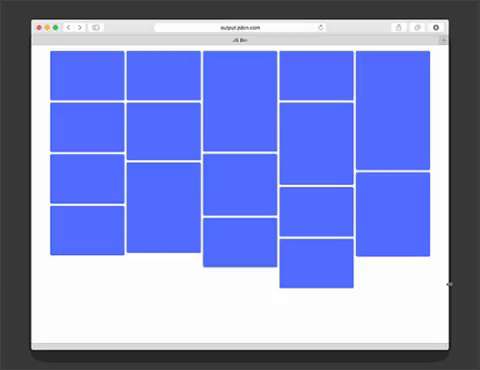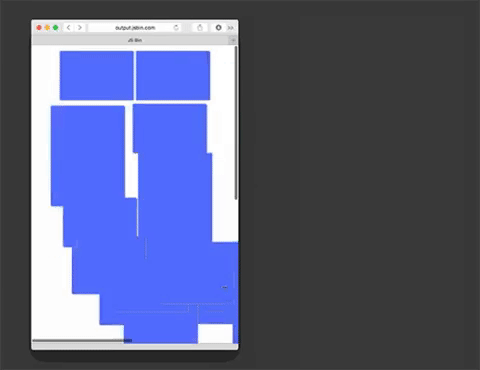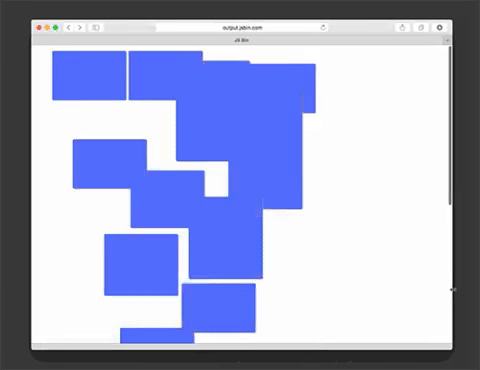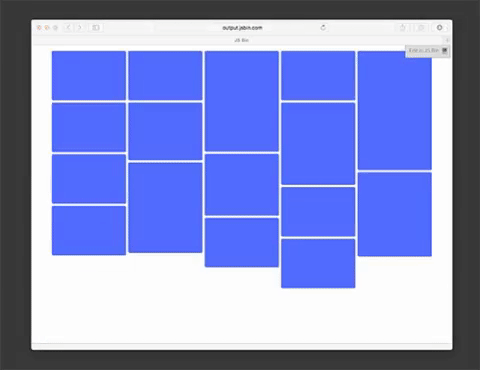
Masonry is a JavaScript grid layout library. It works by placing elements in optimal position based on available vertical space, sort of like a mason fitting stones in a wall. You’ve probably seen it in use all over the Internet.
The code below checks the values: "/", "./", "//", "../", "http", "https". For example, If link "a" is "/myBlog" the code will convert the value to "http://mysite/myBlog".
function createLink($src, $url) {
$scheme = parse_url($url)["scheme"]; // http
$host = parse_url($url)["host"];
if(substr($src, 0, 2) == "//") {
$src = $scheme . ":" . $src;
}
else if(substr($src, 0, 1) == "/") {
$src = $scheme . "://" . $host . $src;
}
else if(substr($src, 0, 2) == "./") {
$src = $scheme . "://" . $host . dirname(parse_url($url)["path"]) . substr($src, 1);
}
else if(substr($src, 0, 3) == "../") {
$src = $scheme . "://" . $host . "/" . $src;
}
else if(substr($src, 0, 5) != "https" && substr($src, 0, 4) != "http") {
$src = $scheme . "://" . $host . "/" . $src;
}
return $src;
}
The code below skipps link (HTML "a" attribute) if it contains "#" or "javascript:" values, because it is not a correct link.
foreach($linkList as $link) {
$href = $link->getAttribute("href");
if(strpos($href, "#") !== false) {
continue;
}
else if(substr($href, 0, 11) == "javascript:") {
continue;
}
$href = createLink($href, $url);
echo $href . "\n";
if(!in_array($href, $alreadyCrawled)) {
$alreadyCrawled[] = $href;
$crawling[] = $href;
// Вставляем href
getDetails($href);
}
private function trimField($string, $characterLimit) {
$dots = strlen($string) > $characterLimit ? "..." : "";
return substr($string, 0, $characterLimit) . $dots;
}
query = $this->con->prepare("SELECT *
FROM sites WHERE title LIKE :term
OR url LIKE :term
OR keywords LIKE :term
OR description LIKE :term
ORDER BY clicks DESC
LIMIT :fromLimit, :pageSize");
if(isset($_POST["linkId"])) {
$query = $con->prepare("UPDATE sites SET clicks = clicks + 1 WHERE id=:id");
$query->bindParam(":id", $_POST["linkId"]);
$query->execute();
if(isset($_POST["src"])) {
$query = $con->prepare("UPDATE images SET broken = 1 WHERE imageUrl=:src");
$query->bindParam(":src", $_POST["src"]);
$query->execute();
$("[data-fancybox]").fancybox({
caption : function( instance, item ) {
var caption = $(this).data('caption') || '';
var siteUrl = $(this).data('siteurl') || '';
if ( item.type === 'image' ) {
caption = (caption.length ? caption + '<br />' : '')
+ '<a href="' + item.src + '">Посмотреть изображение</a><br>'
+ '<a href="' + siteUrl + '">Посетить сайт</a>';
}
return caption;
},
afterShow : function( instance, item ) {
increaseImageClicks(item.src);
}
});