This project focuses on predicting restaurant ratings using features from the Zomato dataset. The workflow involved several key machine learning processes, including Data Exploration, Data Cleaning, Feature Engineering, and Model Building. The insights gathered from thorough Exploratory Data Analysis (EDA) were instrumental in building a robust predictive model.
https://drive.google.com/file/d/1imrTA0uO-rJn4s-tqYGZj3RqAiD9sMtv/view?usp=sharing
Restaurant.mp4
output.mp4
- Online vs. Offline Orders: Around 30,000 orders were online, while about 23,000 were offline, indicating the popularity of online orders.
- Preferred Service Type: Delivery was the most preferred service (50.2%), followed by Dine-out (34.4%).
- Popular Locations: Areas such as BTM and Koramangala have the highest number of restaurants.
- Top Cuisines: North Indian, Chinese, and South Indian cuisines are the most popular among customers.
- Restaurant Types: Quick Bites and Casual Dining were found to be the most common restaurant categories.
- Cost Preference: A meal for two costing around ₹300 was the most preferred price range, with approximately 7,000 orders in that range.
After the data was cleaned and pre-processed, various regression models were implemented to predict restaurant ratings. The following machine learning models were evaluated:
- Linear Regression
- Decision Tree Regressor
- Random Forest Regressor
- Gradient Boosting Regressor
- XGBoost
- XGBoost with Cross-Validation (CV)
Among these, XGBoost with Cross-Validation demonstrated the best performance in terms of accuracy and efficiency. This model was subsequently chosen for deployment. The trained model and label encoders were saved as pickle files for use in the Flask application.
- Flask: A lightweight Python framework used for building the web application.
- Machine Learning: XGBoost was the primary model used for rating predictions.
- HTML/CSS: Used for creating the front-end forms and pages.
- Pickle: For saving the machine learning models and encoders.
- Deployment: The application runs on localhost:5000 and can be dockerized for further deployment on cloud platforms.
The project consists of the following pages and features:
- Allows users to log in before using the rating prediction tool.
- Simple form validation was implemented.

- Displays the main features of the restaurant rating prediction system.
- Users can navigate to the prediction form from here.
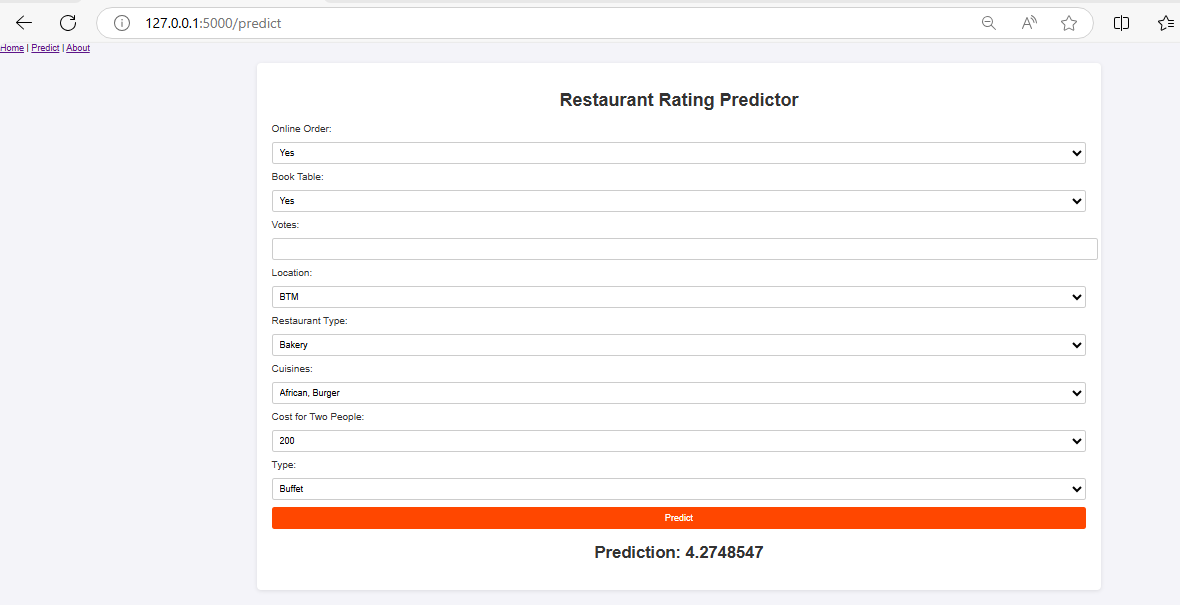
- Users input various restaurant attributes (e.g., location, online order, cuisine) into the form.
- The Flask backend sends these inputs to the machine learning model, and the predicted rating is displayed.
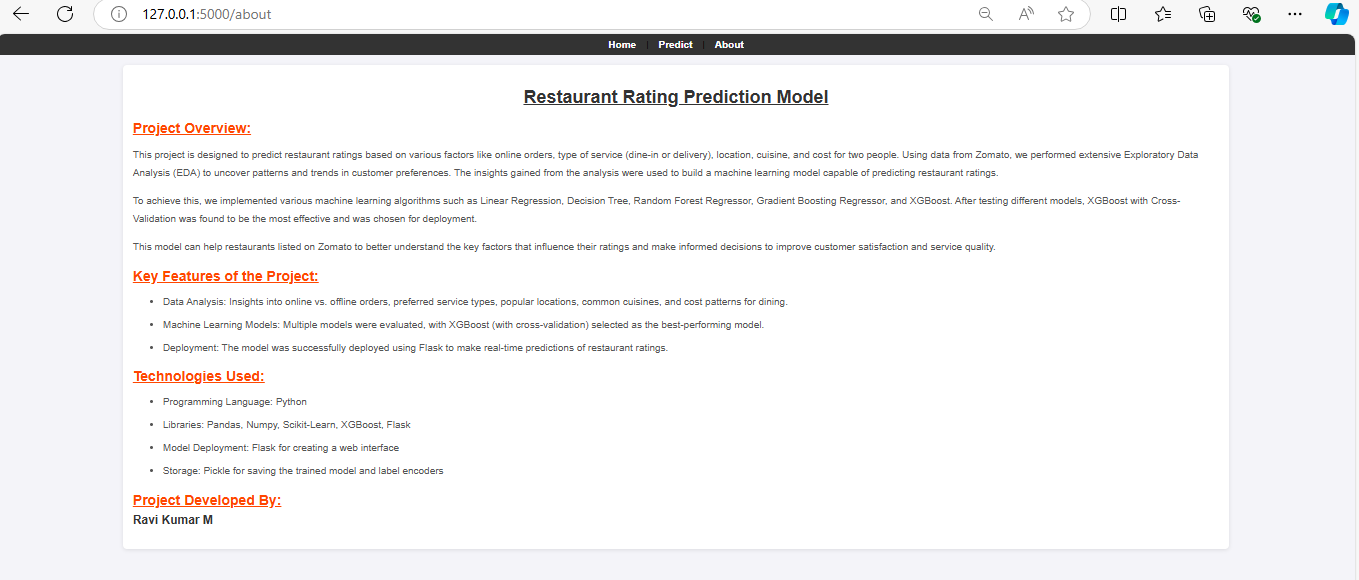
- Page about the project which tells what technology used and how model is implemented.
- The app is deployed locally on Flask and can be accessed via
localhost:5000. - Future deployment options include Dockerizing the application and hosting it on cloud platforms like AWS or Heroku for a live website experience.
- Clone the repository:
git clone https://github.com/yourusername/restaurant-rating-prediction.git cd restaurant-rating-prediction - Run the Flask App:
The application will be available at
python app.py
http://127.0.0.1:5000/.
- Dockerization: Package the application using Docker for easy deployment and scalability.
- Cloud Deployment: Host the live website on platforms such as Heroku, AWS, or Azure for public access.
- User Authentication: Improve user authentication for better security.
- Advanced Features: Add features such as restaurant reviews and sentiment analysis to enhance the prediction model.
The Restaurant Rating Prediction System successfully predicts restaurant ratings based on several key features, offering valuable insights into customer preferences. The use of XGBoost with Cross-Validation ensures accurate and reliable predictions. This project not only serves restaurant owners in making data-driven decisions but also helps customers choose better dining options.
This project is licensed under the MIT License.
This README provides a comprehensive overview of the project, how to run it, and plans for future improvements like Dockerization and cloud deployment. Feel free to customize it further to reflect any additional features or updates you make.