<밑바닥부터 만들면서 배우는 LLM>(길벗, 2025) 책의 공식 코드 저장소로 GPT와 유사한 LLM의 개발, 사전 훈련, 미세 튜닝하기 위한 코드를 포함하고 있습니다.

<밑바닥부터 만들면서 배우는 LLM>에서는 대규모 언어 모델(LLM)이 내부적으로 어떻게 작동하는지 밑바닥부터 단계별로 직접 코딩하면서 배우고 이해합니다. 이 책에서는 명확한 설명, 다이어그램, 예제를 통해 여러분만의 LLM을 만드는 과정을 안내합니다.
이 책에서는 교육적인 목적으로 작지만 완전한 기능을 갖춘 모델을 만듭니다. 이런 모델을 훈련하고 개발하는 방법은 ChatGPT와 같은 대규모 파운데이터션 모델을 만드는 데 사용된 방법과 동일합니다. 또한, 이 책에는 사전 훈련된 모델의 가중치를 불러와 미세 튜닝하는 코드도 포함되어 있습니다.
이 저장소를 다운로드하려면 Download ZIP 버튼을 클릭하거나 터미널에서 다음 명령을 실행하세요:
git clone --depth 1 https://github.com/rickiepark/llm-from-scratch.git이 README.md 파일은 마크다운(Markdown)(.md) 파일입니다. 저장소를 다운로드해서 이 파일을 로컬 컴퓨터에서 보려면 마크다운 에디터나 뷰어를 사용하세요.
깃허브는 마크다운 파일을 자동으로 렌더링해 줍니다.
팁: 로컬 컴퓨터나 클라우드에서 파이썬 환경을 구성하는 가이드를 찾고 있다면 setup 디렉토리 안의 README.md 파일을 참고하세요.
| 제목 | 메인 코드 | 모든 코드 + 부록 |
|---|---|---|
| Setup recommendations | - | - |
| 1장: 대규모 언어 모델 이해하기 | 코드 없음 | - |
| 2장: 텍스트 데이터 다루기 | - ch02.ipynb - dataloader.ipynb (요약) - exercise-solutions.ipynb |
./ch02 |
| 3장: 어텐션 메커니즘 구현하기 | - ch03.ipynb - multihead-attention.ipynb (요약) - exercise-solutions.ipynb |
./ch03 |
| 4장: 밑바닥부터 GPT 모델 구현하기 | - ch04.ipynb - gpt.py (요약) - exercise-solutions.ipynb |
./ch04 |
| 5장: 레이블이 없는 데이터를 활용한 사전 훈련 | - ch05.ipynb - gpt_train.py (요약) - gpt_generate.py (요약) - exercise-solutions.ipynb |
./ch05 |
| 6장: 분류를 위해 미세 튜닝하기 | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb |
./ch06 |
| 7장: 지시를 따르도록 미세 튜닝하기 | - ch07.ipynb - gpt_instruction_finetuning.py (요약) - ollama_evaluate.py (요약) - exercise-solutions.ipynb |
./ch07 |
| 부록 A: 파이토치 소개 | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb |
./appendix-A |
| 부록 B: 참고 및 더 읽을 거리 | 코드 없음 | ./appendix-B |
| 부록 C: 연습문제 해답 | 코드 없음 | ./appendix-C |
| 부록 D: 훈련 루프에 부가 기능 추가하기 | - appendix-D.ipynb | ./appendix-D |
| 부록 E: LoRA를 사용한 파라미터 효율적인 미세 튜닝 | - appendix-E.ipynb | ./appendix-E |
아래 그림이 이 책에서 다룰 내용을 요약해서 보여줍니다.
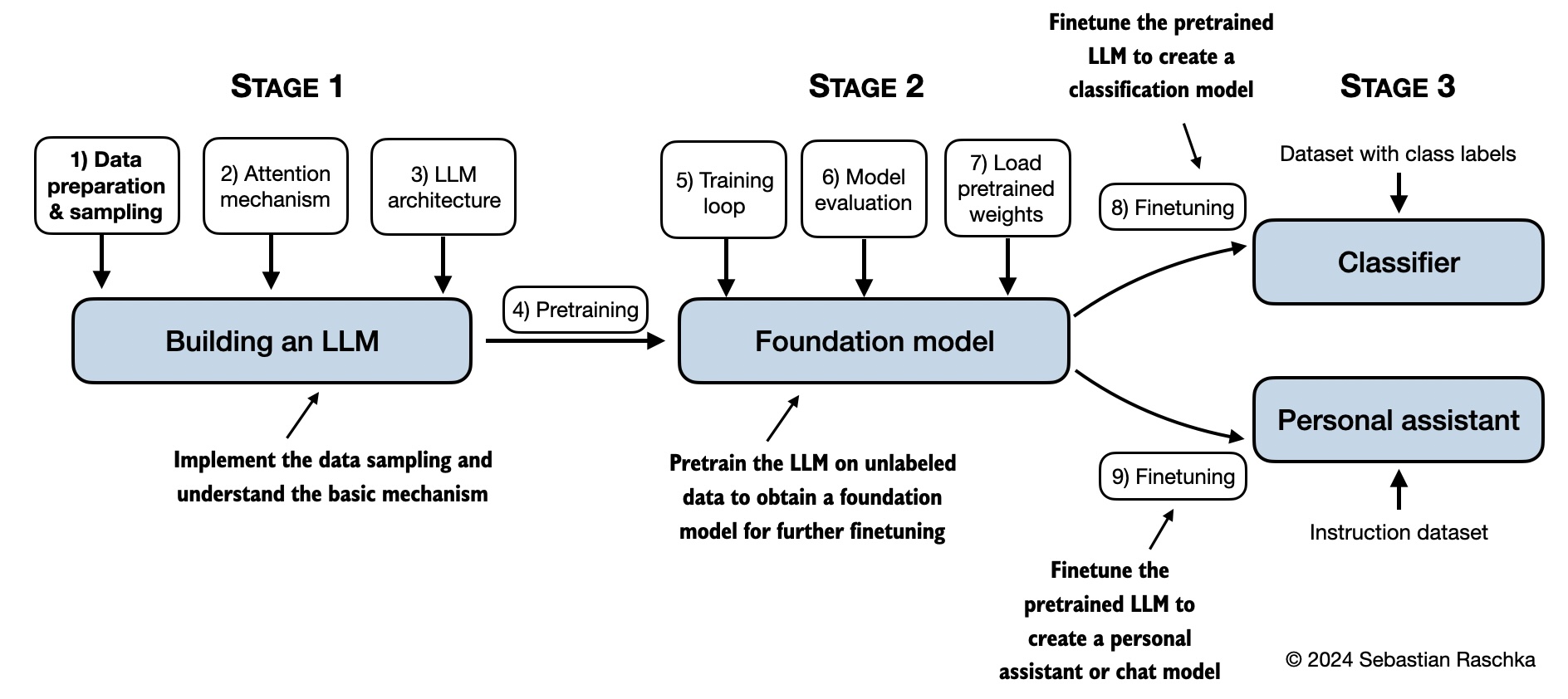
가장 중요한 사전 지식은 파이썬 프로그래밍에 대한 탄탄한 기초입니다. 이를 바탕으로 LLM의 매력적인 세계를 탐험하고 이 책에 제시된 개념과 코드 예제를 충분히 이해할 수 있습니다.
LLM이 심층 신경망을 기반으로 구축되므로 이에 대한 경험이 있다면 일부 개념이 더 익숙하게 느껴질 수 있습니다.
이 책은 외부 LLM 라이브러리를 사용하지 않고 파이토치(PyTorch)를 활용해 코드를 처음부터 구현합니다. 파이토치에 대한 숙련도는 필수는 아니지만, 파이토치의 기본 사항에 익숙하면 분명히 도움이 됩니다. 파이토치가 처음이라면 간략하게 파이토치를 소개하는 부록 A를 참고하세요.
이 책의 주요 장에 포함된 코드는 합리적인 시간 내에 일반 노트북에서 실행될 수 있도록 설계되었으며, 전용 하드웨어가 필요하지 않습니다. 이런 방식을 채택함으로써 더 많은 독자가 쉽게 내용을 따라갈 수 있습니다. 또한, 이 저장소의 코드는 GPU가 사용 가능한 경우 이를 자동으로 활용합니다. (추가 권장 사항은 설정 문서를 참조하세요.)
이 책의 각 장에는 여러 연습문제가 포함되어 있습니다. 해답은 부록 C에 요약되어 있으며, 해당 코드 노트북은 이 저장소의 주요 장 폴더(예: ./ch02/01_main-chapter-code/exercise-solutions.ipynb)에서 확인할 수 있습니다.
코드 연습문제 외에도, 본문과 별도로 140페이지 분량의 워크북이 함께 제공됩니다. 워크북에는 장당 약 30개의 퀴즈 문제와 해답이 포함되어 있어, 학습 내용을 점검하는 데 도움이 될 것입니다.

관심있는 독자를 위해 몇몇 폴더에 추가 자료가 담겨 있습니다:
- 설정
- 2장: 텍스트 데이터 다루기
- 3장: 어텐션 메커니즘 구현하기
- 4장: 밑바닥부터 GPT 모델 구현하기
- 5장: 레이블이 없는 데이터를 활용한 사전 훈련
- Alternative Weight Loading Methods
- Pretraining GPT on the Project Gutenberg Dataset
- Adding Bells and Whistles to the Training Loop
- Optimizing Hyperparameters for Pretraining
- Building a User Interface to Interact With the Pretrained LLM
- Converting GPT to Llama
- Llama 3.2 From Scratch
- Qwen3 Dense and Mixture-of-Experts (MoE) From Scratch
- Gemma 3 From Scratch
- Memory-efficient Model Weight Loading
- Extending the Tiktoken BPE Tokenizer with New Tokens
- PyTorch Performance Tips for Faster LLM Training
- 6장: 분류를 위해 미세 튜닝하기
- 7장: 지시를 따르도록 미세 튜닝하기
- Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries
- Evaluating Instruction Responses Using the OpenAI API and Ollama
- Generating a Dataset for Instruction Finetuning
- Improving a Dataset for Instruction Finetuning
- Generating a Preference Dataset with Llama 3.1 70B and Ollama
- Direct Preference Optimization (DPO) for LLM Alignment
- Building a User Interface to Interact With the Instruction Finetuned GPT Model