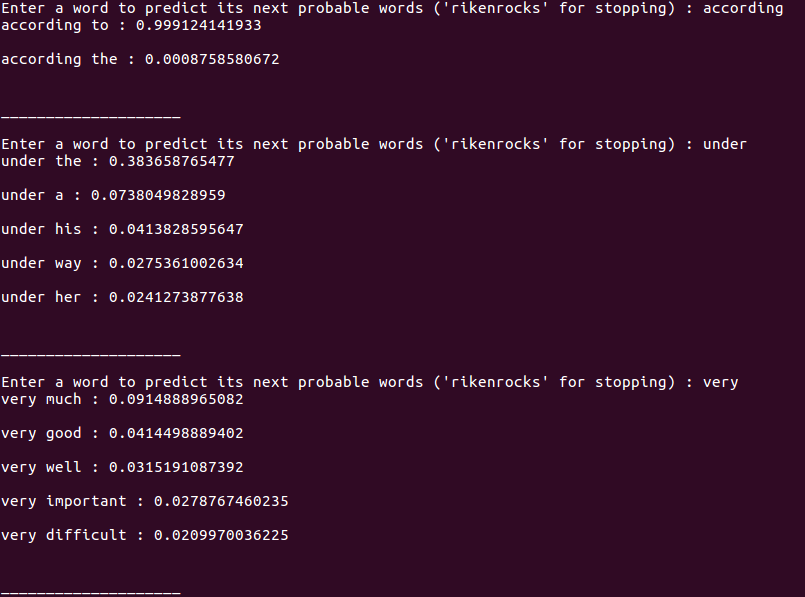
This is a N-gram language model that predicts the next word based on a precalculated conditional probability. This model is trained on bigrams from COCA corpus which can be downloaded from this link.
- Download the bigram dataset from above provided link. You will need to register with an email ID for doing so. There are three files for bigram model.
- Non case sensitive - w2_.zip
- Case sensitive - w2.zip
- Case sensitive with POS tagging - w2c.zip
We need only the Non case sensitive zip.
-
Extract the Non case sensitive zip. You will get w2_.txt file. Put this file in the same folder where the scripts 'getTopBigram.py' and 'bigramConditionalProbability.py' are there.
-
Make a new directory named
pickleDumps. -
Run 'bigramConditionalProbability.py' file using
python bigramConditionalProbability.py. Note that you will need to havepicklemodule installed before that. You can install it usingpip install pickle. (It would be recommended to have a virtual environment for such stuff). Previous command will create some pickle dumps inpickleDumpsdirectory. -
Run
python getTopBigram.pyand enjoy :p.