A machine learning project that categorizes news articles from headlines using a fine-tuned DistilBERT model, trained on nearly 210,000 news articles from 2012 to 2022 from Huffpost.
DistilBERT is a distilled version of BERT that retains 97% of BERT's language understanding whilst being 60% smaller and significantly faster. The pre-trained model has been trained on the News Category Dataset from Kaggle which consists of around 210k headlines.
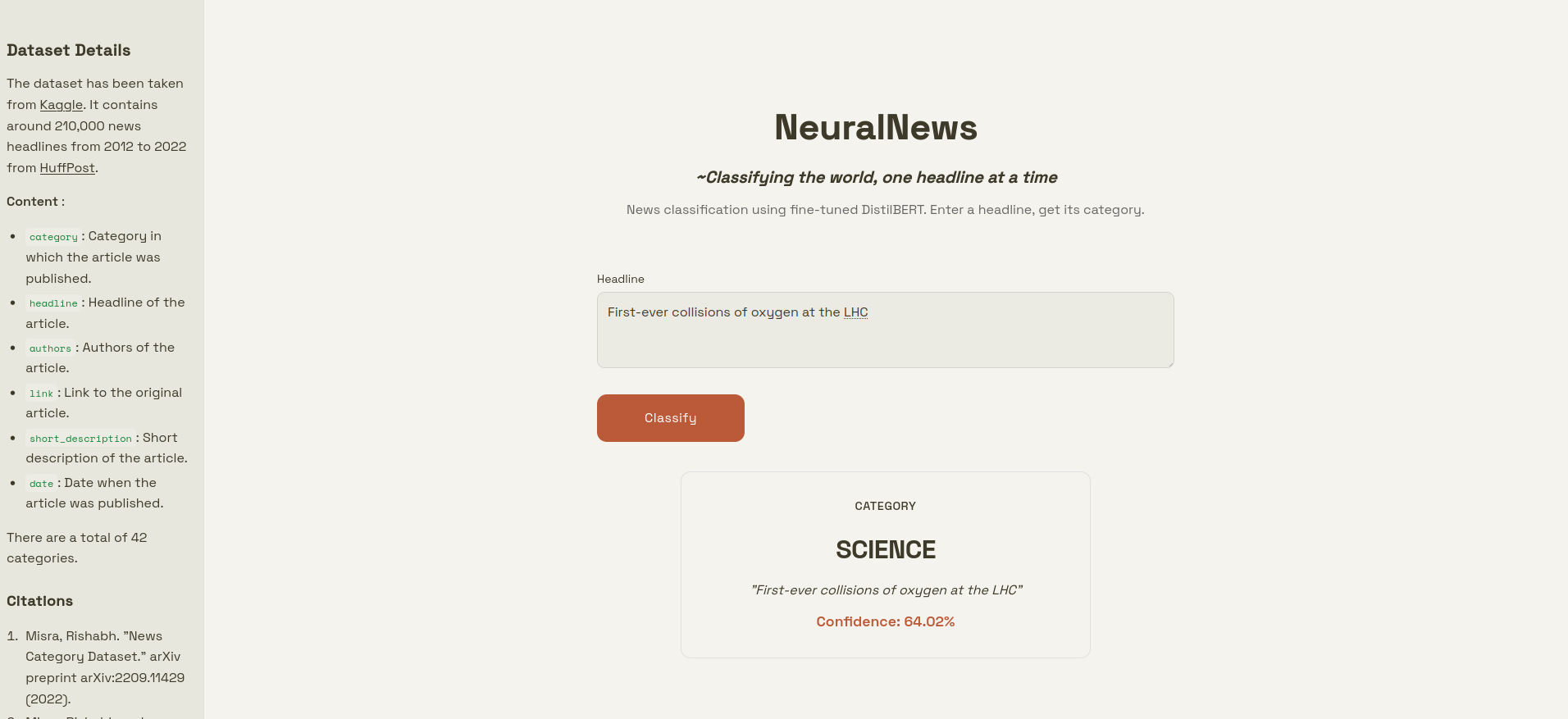
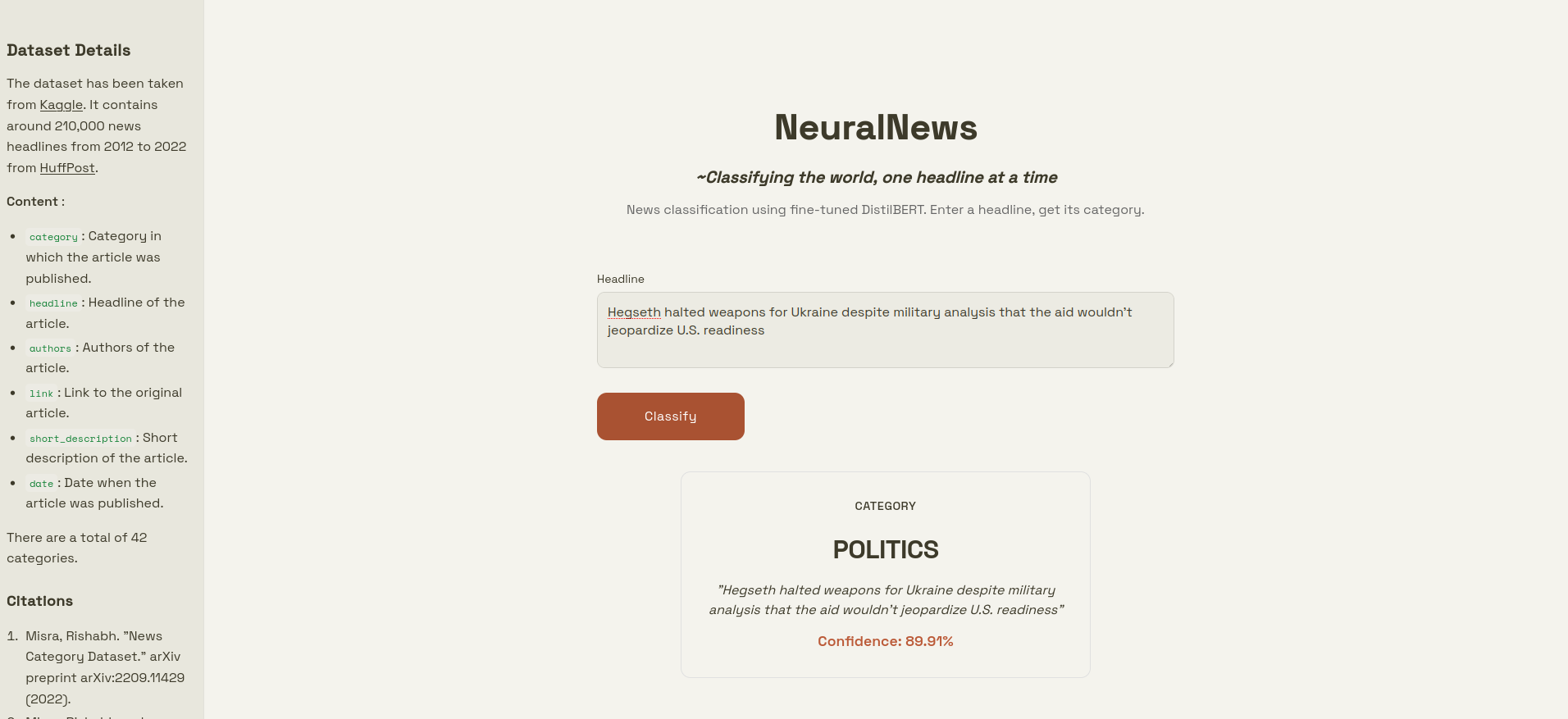
The dataset used has been taken from Kaggle.
category: Category in which the article was published.headline: Headline of the article.authors: Authors of the article.link: Link to the original article.short_description: Short description of the article.date: Date when the article was published.
There are a total of 42 categories.
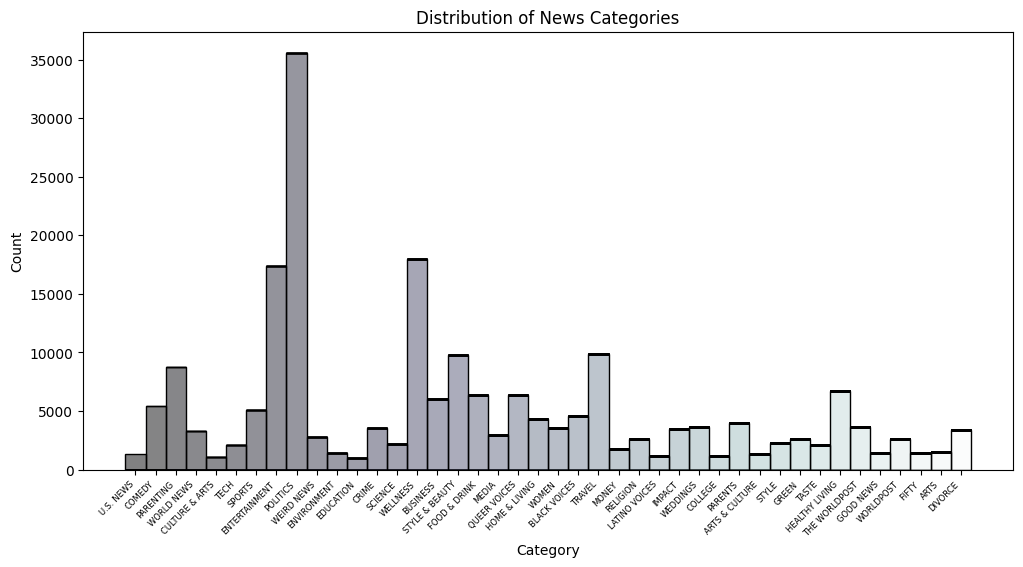
The model achieved an accuracy of nearly 65%, on both the validation and test data.
- Misra, Rishabh. "News Category Dataset." arXiv preprint arXiv:2209.11429 (2022).
- Misra, Rishabh and Jigyasa Grover. "Sculpting Data for ML: The first act of Machine Learning." ISBN 9798585463570 (2021).
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
- Fork the repository
- Create your feature branch (
git checkout -b feature/AmazingFeature) - Commit your changes (
git commit -m 'Add some AmazingFeature') - Push to the branch (
git push origin feature/AmazingFeature) - Open a Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
Note
The License does not cover the dataset. It has been taken from Kaggle.