General:
This repo contains torch implementations for 1) YoloV4 and 2) Recurrent YoloV4 that utilize RNNs on the bounding box trajectories. The approach in 2) is novel since we are using more recent RNNs, a UR-LSTM and HiPPO LSTM to model temporal dependencies between consceucitive bounding box trajectories.
A short demo of our YoloV4 still image detection system trained on MS COCO 2017 can be seen in Fig. 1. The full demonstration can be found here.
The short demo for YoloV4, UrYolo and Holo trained on ImageNet VID 2015 can be seen in Fig. 2.




Example Dictionary Structure
View dictionary structure
.
├── application # Real time inference tools
└── __init__.py
└── yolo_watches_you.py # Yolo inference on webcam or video you choose
├── cpts # Weights as checkpoint .cpt files
└── ...
└── efficentnet_yolov4_mscoco.cpt # Pretrained yolov4 still-image detector
└── efficentnet_yolov4_imagenetvid.cpt # Pretrained yolov4 video detector
├── figures # Figures and graphs
└── ....
├── loss # Custom PyTorch loss
└── __init__.py
└── yolov4_loss.py
├── models # Pytorch models
└── __init__.py
└── rnn.py # Rnns in base torch (simple, gru, lstm)
└── yolov4.py # yolov4 architecture in base torch
├── results # Result textfiles
└── ....
├── train # Training files
└── __init__.py
└── train_rnn.py
└── train_yolo.py
├── utils # Tools and utilities
└── __init__.py
└── coco_json_to_yolo.py
└── create_csv.py
└── get_mscoco2017.sh
└── graphs.py
└── utils.py
├── requierments.txt # Python libraries
├── setup.py
├── terminal.ipynb # If you want to run experiments from a notebook or on google collab
├── LICENSE
└── README.md
Getting started:
In order to get started first cd into the ./yolov4-real-time-obj-detection dictionary and run the following lines:
virtualenv -p python3 venv
source venv/bin/activate
pip install -e .
Depending on what libraries you may already have, you may wish to pip install -r requirements.txt. To run our validation or sanity check experiments the MNIST data set is requiered, which torch will download for you, so there is nothing you need to do. However, to train the video object detector from scratch, you will need 1) the MS COCO VOC and 2) ImageNet VID data-set. You can download MS COCO VOC manually or by calling the following shell file: utils/get_mscocovoc_data.sh, which will automatically download and sort the data into the approriate folders and format for training. For ImageNet VID) you will have to sign up, request access and download the data by following the website guide.
Training:
If you would like to train and replicate our results yourself please run the following commands:
For the SMNIST task:
python3 main.py --model_name rnn --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
python3 main.py --model_name gru --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
python3 main.py --model_name lstm --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
python3 main.py --model_name urlstm --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
python3 main.py --model_name hippo --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
python3 main.py --model_name gatedhippo --dataset_name mnist --hidden_size 512 --input_size 1 --output_size 10 --nepochs 50 --nruns 5 --weight_decay 0.00 --lr 1e-3
For YoloV4 on MSCOCO2017:
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=8 python3 train/train_ddp_yolo.py --batch_size 64 --nepochs 300 --save_model True --ngpus 1
For YoloV4 and its recurrent variants UrYolo and Holo please run:
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=4 python3 train/train_holo_enas_vid.py --ngpus 1 --batch_size 32 --seq_len 8 --nclasses 30 -
-gate none --hidden_size 1024 --weight_decay 0.00 --momentum 0.937 --pretrained True --lr 1e-3 --nepochs 100
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=4 python3 train/train_holo_enas_vid.py --ngpus 1 --batch_size 32 --seq_len 8 --nclasses 30 -
-gate urlstm --hidden_size 1024 --weight_decay 0.00 --momentum 0.937 --pretrained True --lr 1e-3 --nepochs 100
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=4 python3 train/train_holo_enas_vid.py --ngpus 1 --batch_size 32 --seq_len 8 --nclasses 30 -
-gate hippolstm --hidden_size 1024 --weight_decay 0.00 --momentum 0.937 --pretrained True --lr 1e-3 --nepochs 100
Pretrained Checkpoints:
Pretrained checkpoints can be downloaded from here. You can download the entire cpts folder and replace with the cpts folder in the repo. For those who want to train on ImageNet and want to utilise our pretrained backbone trained on MSCOCO, you may only be interested in the pretrained mscoco weight.
Results SMNIST:
Loss and accuracy values are computed every epoch. See in Fig.3 and 4 for training vs. test loss and accuarcy.
adjustments.


Results Yolo MSCOCO2017:
Loss and mean average precision (mAP) values are computed after every 10th epoch and can are printed during training in the terminal. See in Fig.5 and 6 for training vs. test loss and mAP@0.5. We skip computing mAP, recall and precision for the training data-set due to the large computational cost. That is, because computing these metrics requieres to iterate over the entire data-set i.e., test or train, given that MSCOCO2017 has over 100K training examples, each example with more than one or two bounding box annotations, the metric needs to be computer over a large quantitity, making it computationaly time consuming, especially when the model has not converged yet.
| Metric | Train | Test |
|---|---|---|
| Class accuracy | 0.899 | 0.785 |
| Object accuracy | 0.501 | 0.449 |
| No object accuracy | 0.996 | 0.997 |
| mAP@0.5 | − | 0.468 |
| Recall | − | 0.561 |
| Precision | − | 0.587 |
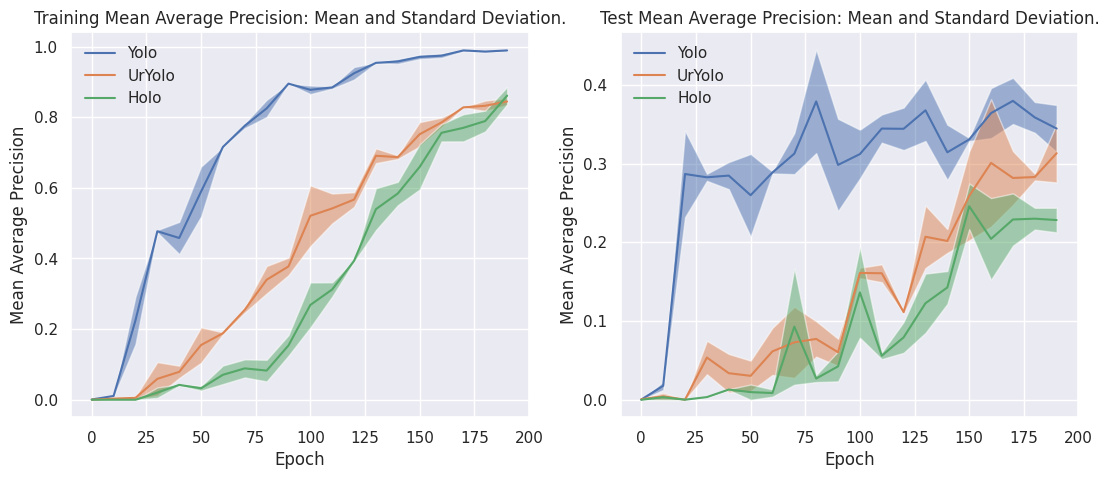
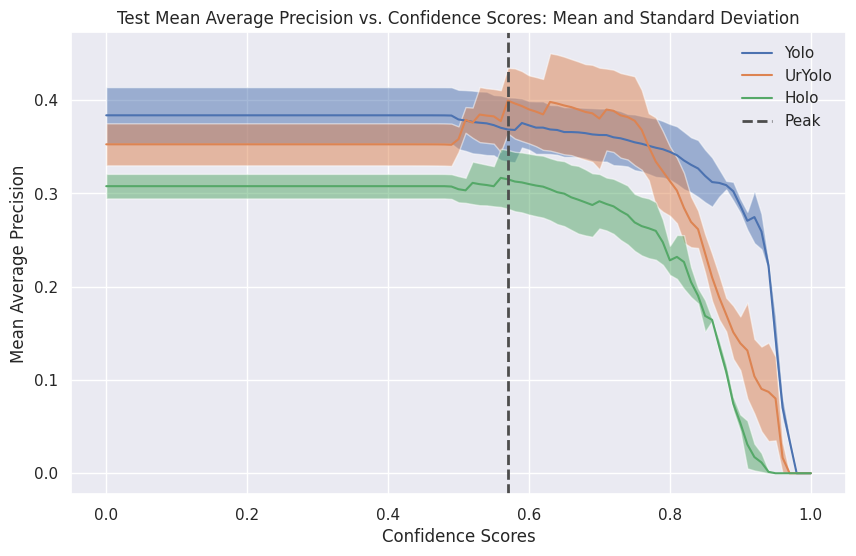
Results Yolo ImageNetVID2015:
Loss and mean average precision (mAP) values are computed after every 10th epoch and can are printed during training in the terminal. See in Fig.5 and 6 for training vs. test loss and mAP@0.5.
adjustments.