Exploring Communication Complexity: A Study of Language Patterns in Social Media and Programming Languages
This master's thesis project, conducted as part of the MSc in Computational Software Techniques in Engineering of Cranfield University, aims to explore the inherent complexities in language that reflect the unpredictability and intricate patterns of human communication.
By leveraging entropy as a quantifiable measure of this complexity, the study captures the pattern and nuances within various forms of interaction, including social media, literature, and programming languages.
- Introduction
- Data
- Data Acquisition
- Preprocessing
- NLP
- Entropy Estimation
- Analysis
- Workflows
- Deliverables
- Languages Studied: English (EN), French (FR), Spanish (ES)
- Programming Languages: C++, Python, Java
- Datasets: 7 Custom Datasets
- Data Collection: +300 Millions of Tweets Collected, ~80Gb of Data processed
- Entropy Estimators: 3 Families, 7 Plug-In Entropy Estimators
- Analysis: 8 NLP Analyses, 2 Methods of Uncertainty Analysis
- Literature: 5 Books Examined
- Global Events Studied: Covid-19, Ukraine War
- Explore Entropy in Language: Analyzing major languages on Twitter.
- Analyze Linguistic Chaos in Twitter: Examine word usage, accents, emojis, punctuation.
- Investigate Literature Noisy Entropy: Assess noisy characteristics in literature books.
- Map Noisy Environments: Focus on contexts such as COVID-19 and the Ukraine War.
- Examine Human Emotion: Uncover emotional patterns and entropy across languages.
- Assess Media Language Styles: Study news outlets' unique entropy patterns.
- Contrast Personal Communication Tactics: Compare entropy in public figure tweets.
- Analyze Entropy over Time: Investigate entropy changes during significant global events.
- Explore Programming Languages Entropy: Study variables, strings, numbers in programming languages.
- Plug-In Estimators: Non-parametric approach reflecting complexity at the token level without considering context.
- Entropy Rate: Measures uncertainty per symbol/token, capturing long-term behavior.
- Prediction by Partial Matching (PPM): Context-based adaptive technique offering a flexible approach.
- Character-Level Insights: Novel estimates of ~4.35 bits, surpassing previous works.
- Word-level Insights: Confirms prior work, observes a 3-bit shift with context consideration.
- Character Complexity: Aligns with literature; chaos resides in word formation.
- Unigram Entropy: 10-11 bits, highlighted by hapax legomena (2 bits above past studies).
- Contextual Shift: A consistent 3-bit shift reveals logical structure despite noise.
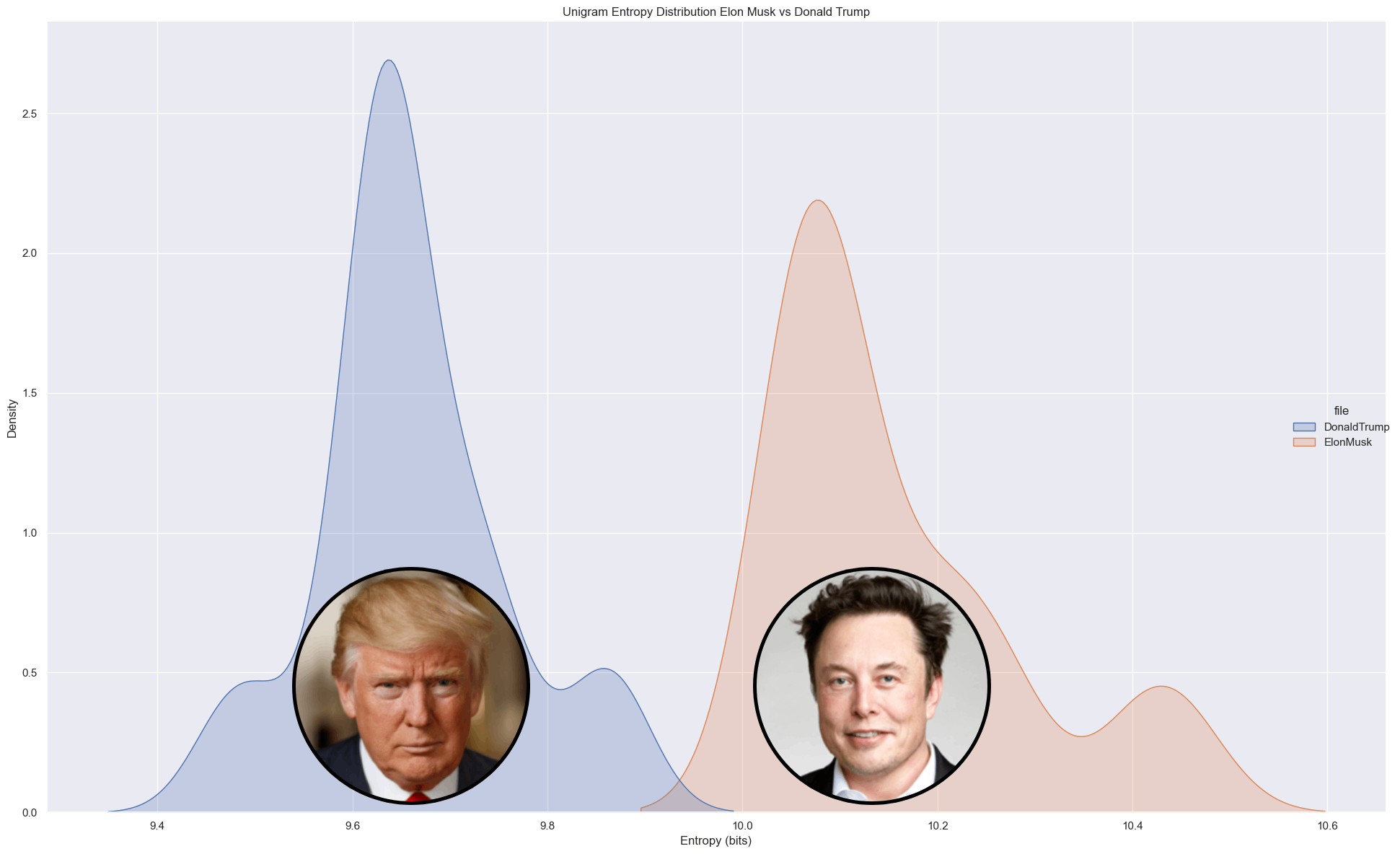
- Public Figures: Contrast in entropy between Musk (technical diversity) and Trump (political discourse).
- Political Structure: Repeated patterns in politics converge public opinion; low entropy.
- Comparison: Entropy Rate comparison between Donald Trump and Elon Musk.
- Symbols and Structure: Accents, emojis increase entropy; punctuation reduces it, defying traditional beliefs.
- Emotional Patterns: Universal low entropy in inherent emotions like love & fear.
- Media Bias: News outlet styles reveal unique entropy, hinting at bias detection capabilities.
- Global Events: COVID-19, Ukraine War show unigram entropy convergence, highlights societal response, unity.
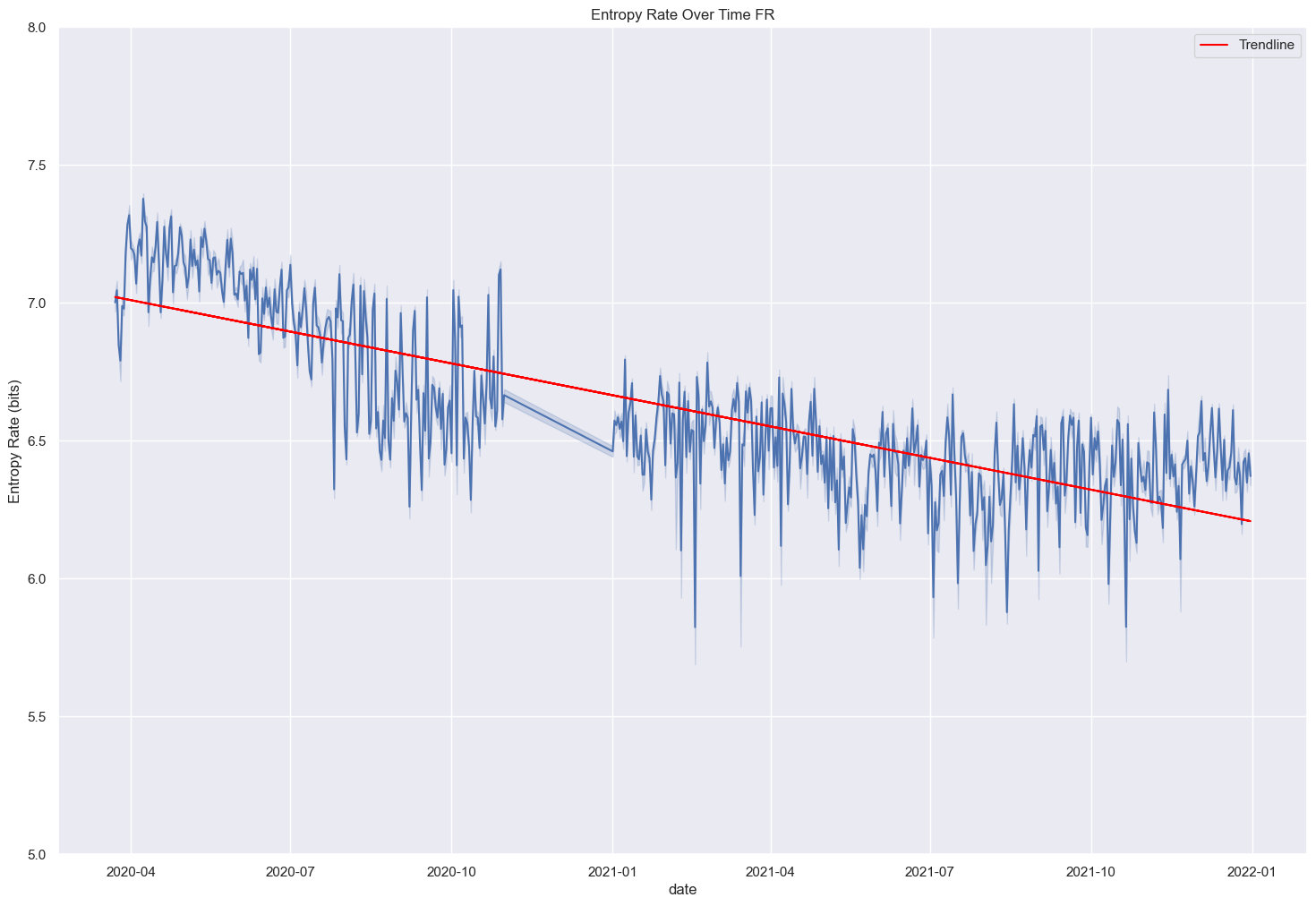
- Language Evolution: Decline in entropy signifies societal adaptation, convergence in viewpoints.
- Trend Analysis: Entropy Rate trend over time of the Covid-19 French dataset.
- Universality: Common features in C++, Python, Java.
- Predictable Structure: Low Entropy Rate highlights codified patterns and conventions.
- Source of Noise: Variable and function naming contribute most to complexity.
The data use for this project is a mix of Social Media data and Computer Language data.
For the Social Media data, Twitter was used as the main source. The data was collected using scraping, streaming and Twitter API. A total of around 200-300 million tweets were collected, using different methods.
To comply with Twitter's Terms of Service, the data used in this project is only shared dehydrated. Which means that the data is shared in the form of tweet ids, and not the full tweet.
A script to hydrate the data is provided in the dataAcquisition folder, as well as a script to dehydrate the data.
For the Computer Language data, CodeNet was used as the main source. CodeNet is a large-scale, high-quality dataset of programmatic source code. It contains 14M code samples from 55 programming languages, and is available for download here.
Due to different License restrictions, the dataset was not created by scratch using GitHub data. Instead, the dataset was downloaded from the official website and used as is.

Collect data from Twitter using scraping, streaming and Twitter API.
Learn more about the data collection here.
Pre-processing of the data includes the following steps:
- Cleaning
- Data Manipulation
- Tokenization
Learn more about the pre-processing here.
Natural Language Processing (NLP) is used to label the tweets. The labels are then used to filter the data and to perform the analysis on clusters.
The NLP analysis includes:
- Emotion Analysis
- Hate Speech Detection
- Irony Detection
- Language Detection
- Named Entity Recognition
- Offensive Language Detection
- Sentiment Analysis
- Topic Detection
Learn more about the NLP analysis here.
The entropy estimation used different methods to estimate the entropy of the text. The methods used are:
- Plug-in Estimators (unigrams)
- Maximum Likelihood (ML)
- Miller-Maddow (MM)
- Chao-Shen (CS)
- Schurmann-Grassberger (SG)
- Shrinkage (SH)
- Laplace
- Jeffrey
- Minimax
- NSB
- Entropy Rate
- Prediction by Partial Matching (PPM)
On top of the entropy estimators Bootstrap is used to estimate the confidence interval of the entropy.
Learn more about the entropy estimation here.
The Analysis is designed to generated graphs and extract insights from the performed analysis.
There is two types of analysis:
- Analysis (Preliminary Analysis and Exploratory Analysis)
- Results Analysis (Analysis of the results of the entropy estimation)
Learn more about the analysis here.
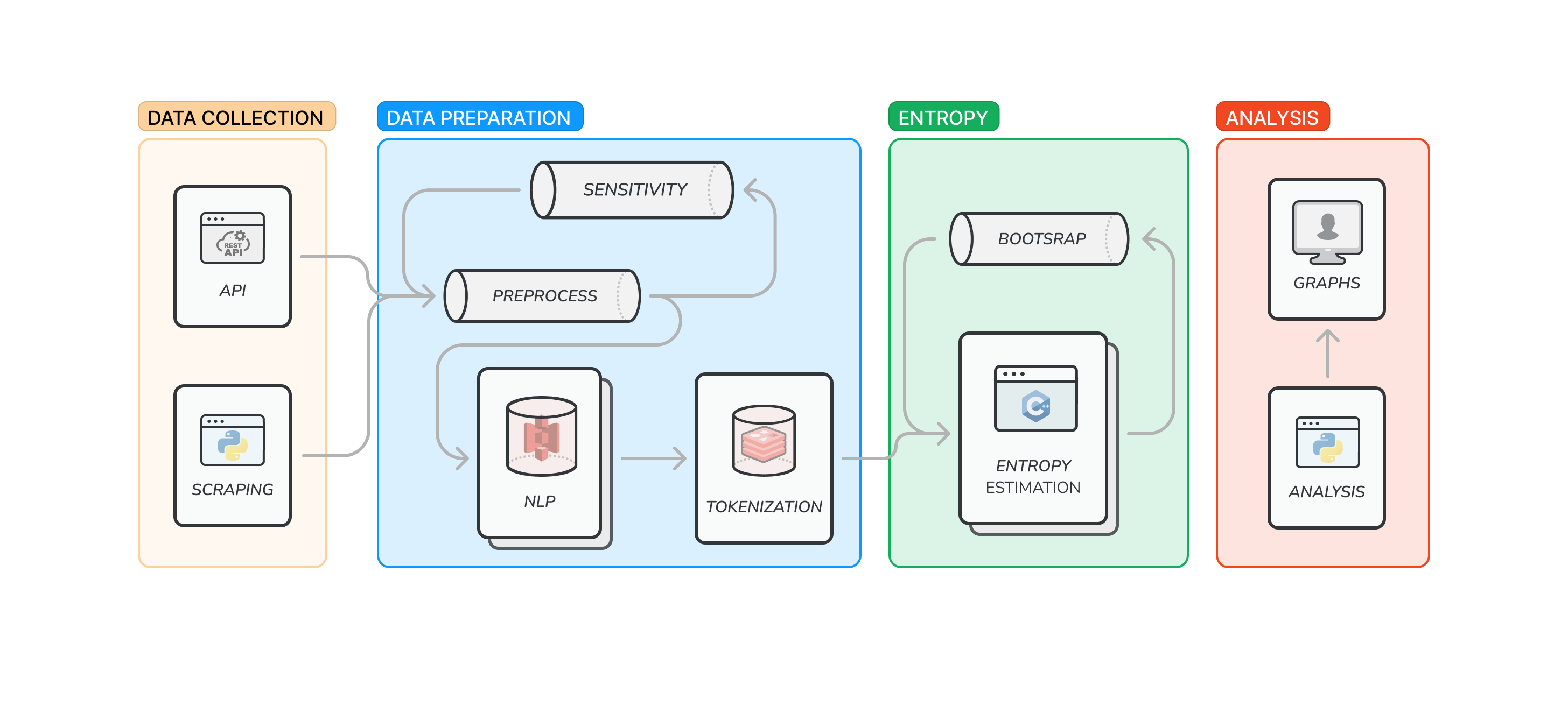
Here is the general workflow of the project:
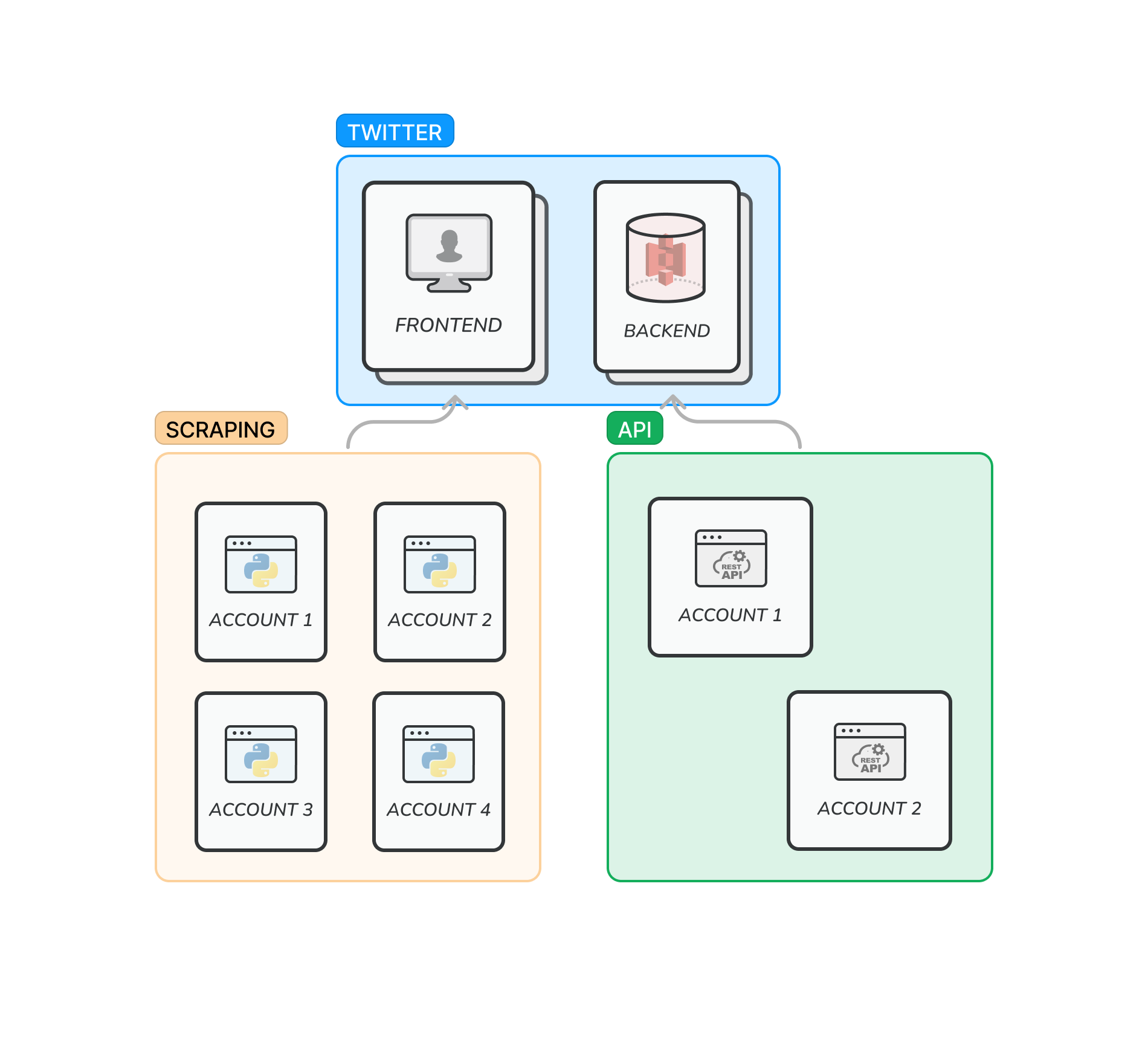
Here is the environment of the data acquisition workflow:
The master's thesis is available here.
Find the poster here.

Individual Research Project 2022/2023
Copyright © 2023 by Siméon FEREZ. All rights reserved.