Il progetto nella repository prevede la seguente oranizzazione:
- TestDataSet
- data
- images_output
- test_files
- support
- init.py
- dirManage.py
- dsLoad.py
- graphs.py
- write.py
- decisionTree_classifier.py
- decisionTree_classifier_HO.py
- KNN_classifier.py
- KNN_classifier_HO.py
- randomForest_classifier.py
- randomForest_classifier_HO.py
- SVM_classifier.py
- SVM_classifier_HO.py
- MPL_classifier.py
- MPL_classifier_HO.py
Nella seguente tabella viene mostrato il contenuto siogni cartella o file
| Nome | Tipo | Descrizione |
|---|---|---|
| TestDataSet | Direcrtory | Directory principale del progetto contiene tutte le dir/file sottostanti |
| data | Direcrtory | Directory contenete i due dataset sul quale si effettuano i test MNIST F-MNIST |
| images_output | Directory | Directory contenente i test grafici generati automaticamente dagli script python |
| test_files | Directory | Directory contenente i file di testo nel quale vengono annotati i risultati dei test |
| support | Package Python | Package contenente script python di supporto |
| decisionTree_classifier.py | File Python | Script per addestrare un albero decisionale su dataset MNIST/F-MNIST |
| decisionTree_classifier_HO.py | File Python | Script per testare gli Iper-parametri dell' albero decisionale per ottenere la maggiore accuratezza |
| KNN_classifier.py | File Python | Script per addestrare una KNN su dataset MNIST/F-MNIST |
| KNN_classifier_HO.py | File Python | Script per testare gli Iper-parametri della KNN per ottenere la maggiore accuratezza |
| randomForest_classifier.py | File Python | Script per addestrare una foresta randomica su dataset MNIST/F-MNIST |
| randomForest_classifier_HO.py | File Python | Script per testare gli Iper-parametri della foresta randomica per ottenere la maggiore accuratezza |
| SVM_classifier.py | File Python | Script per addestrare una SVM su dataset MNIST/F-MNIST |
| SVM_classifier_HO.py | File Python | Script per testare gli Iper-parametri della SVM per ottenere la maggiore accuratezza |
| MPL_classifier.py | File Python | Script per addestrare una MPL su dataset MNIST/F-MNIST |
| MPL_classifier_HO.py | File Python | Script per testare gli Iper-parametri del MPL per ottenere la maggiore accuratezza |
La sub-directory images_output conterrà a suo interno le directory create automaticamente dagli script nel quale ci saranno i Grafici di accuratezza dei test effettuati sui vari classificatori.
La sub-directory test_filesinvece conterrà a suo interno i file:
Test_History.txt: Conterrà i risultati ottenuti dai test effettuati sui classificatori;HO_History.txt: Conterrà i risultati ottenutti dai test effettuati combinando i vari Iper-parametri sui classificatori;
Se si vuole caricare il progetto manualmente tenere conto della gerarchia sopra mostrata altrimenti scaricare la repository in formato .zip che permette di caricare autmaticamete il progetto sul proprio IDE (io ho utilizzato PyCharm).
In questa sezione si è analizzato l'utilizzo di alcuni dei più famosi classificatori nel ML addestrati sui set di dati MNIST e F-MNIST e i loro risultati sono stati messi a confronto per dedurre quali dei due dataset sia il più efficiente, tenendo conto di un importantissimo aspetto ossia che il dataset MNIST sia più semplice di F-MNIST, per approfondire l'argomento visitare la repository di zalandoresearch.
I classificatori utilizzati sono stati:
- K-Neighbors Classifier
- Alberi decisionali
- Foreste Casuali
- Macchina a vettori di supporto (SVM)
- Percettrone Multinastro (MPL) [Particolare architettura delle reti neurali artificiali]
Per rendere utilizzabili i dataset MNIST e F-MNIEST, questi sono stati importati nel progetto da locale.
Come prima accennato i file zip contenenti il dataset sono presenti rispettivamente nelle directory data/MNIST e data/FMNIST e per importarli sono state utilizzate le funzioni load_mnist(path="percorso") e load_f_mnist_mnist(path="percorso", kind="train"), presente nello script dsLoad.py.
from support.mnist import load_mnist, load_f_mnist
# Caricamento dei dati di MNIST all'interno dei vettori di train e di test
X_train, X_test, Y_train, Y_test = load_mnist(path="data/MNIST")
# Caricamento dei dati di F-MNIST all'interno dei vettori di train e di test
X_train, Y_train = load_f_mnist(path='data/FMNIST', kind='train')
X_test, Y_test = load_f_mnist(path='data/FMNIST', kind='t10k')Di seguito viene mostrato il blocco di codice utilizzato per ottenere le info utili sui dataset che sono servite poi per effettuare dei test ottimali:
# sul dataset
# dimensioni del set di train
print("Dimensions TRAIN SET: ",X_train.shape, "\n")
print("Dimensions TEST SET: ",X_test.shape, "\n")
# data types
print(X_train.info())
print(X_test.info())I risultati ottenuti sono i seguenti:
Dimensions TRAIN SET: (60000, 784)
Dimensions TEST SET: (10000, 784)
class: ndarray
shape: (60000, 784)
strides: (784, 1)
itemsize: 1
aligned: True
contiguous: True
fortran: False
data pointer: 0x7fdcd9c00000
byteorder: little
byteswap: False
type: uint8
None
class: ndarray
shape: (10000, 784)
strides: (784, 1)
itemsize: 1
aligned: True
contiguous: True
fortran: False
data pointer: 0x7fdcdc8dd000
byteorder: little
byteswap: False
type: uint8
None
Le API dei classificatori utilizzati per essere addestrati sui set di train e di test sono stati importati dalla libreria sklearn. Per maggiori informazioni sulla libreria sklearn.
# Classificatore KNN
from sklearn.neighbors import KNeighborsClassifier
# Alberi decisionali
from sklearn.tree import DecisionTreeClassifier
# Foreste Randomiche
from sklearn.ensemble import RandomForestClassifier
# Macchina a vettori di supporto SVM
from sklearn.svm import SVC
# Percettrone Multinastro MPL
from sklearn.neural_network import MLPClassifierAltre API da sklearn utilizzate:
# Per portare i sets sulla stessa scala (0-1)
from sklearn.preprocessing import MinMaxScaler
# Errore quadratico medio per il controllo dell'overfitting
from sklearn.metrics mean_squared_error
# Per calcolare l'accuratezza della stima
from sklearn.metrics import accuracy_score
# Per misurare il modo in cui sono statedeterminate le stime
from sklearn.metrics import log_loss
# Per mostrare la ripartizione dell'accuratezza tra le varie classi di predizione
from sklearn.metrics import classification_report
# Per creare il modello che effettua delle stime di predizione combinando vari Iper-parametri
from sklearn.model_selection import GridSearchCVPer l'output grafico invece sono state realizzate delle funzioni ex novo che fanno uso di altre funzioni della libreria matplotlib. Per maggiori informazioni sulla libreria matplotlib.
from support.grafics import printConfMatrix, printErroneusClassificationsMNIST, printErroneusClassificationsFMNIST, printAccGraph, printAccGraphSVM| Funzione | Compito |
|---|---|
| printConfMatrix(...param) | Genera un immagine .png della matrice di confusione su un set di dati |
| printErroneusClassificationsMNIST(...param) | Genera le immagini .png dei primi 100 elementi classificati in modo errato su MNIST |
| printErroneusClassificationsFMNIST(...param) | Genera le immagini .png dei primi 100 elementi classificati in modo errato su F-MNIST |
| printErroneusClassificationsFMNIST(...param) | Genera le immagini .png dei primi 100 elementi classificati in modo errato su F-MNIST |
| printAccGraph(...param) | Genera un immagine .png del grafico di accuratezza tra train set e test set |
| printAccGraphSVM(...param) | Genera un immagine .png del grafico di accuratezza tra train set e test set per SVM |
Per annotare i risultati dei test nei due file di testo è stata usata una funzione ex novo che fa uso della funzione builtins per la scrittura/lettura dei file offerta da python.
from support.writer import writeAppend | Funzione | Compito |
|---|---|
| writeAppend(...param) | Apre il file specificato tra i parametri e vi scrive al suo interno il testo specificato nei parametri |
Per creare automaticamente le directory è stata usata una funzione ex novo che fa uso della funzione makedirs(...) messa a disposizione dalla libreria os
from from support.dirManage import newDirectoryTest | Funzione | Compito |
|---|---|
| newDirectoryTest(...param) | Crea una nuova directory nel percorso specificato tra i parametri |
Come si può evincere dalla tabella che schematizza la struttura del progetto esistono due tipologie di script:
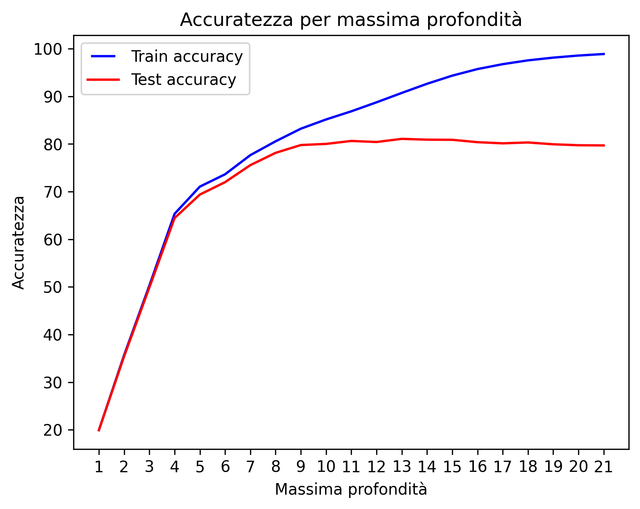
- [nome_classificatore]_classifier_HO.py: Dato un dizionario di Iper-parametri, scelti accuratamente tra tutti i possibili perche influiscono su accuratezza e tempi di addestramento del modello, simula diversi test combinando questi ultimi e li organizza in modo decrescente in termini di accuratezza in un dataFrame. I risultati possono essere consultati sul file di tetso destinato ad annotarli e infine genera un grafo che mostra l'accuratezza del set di train e di test in base al parametro che più influisce sull'accuratezza.
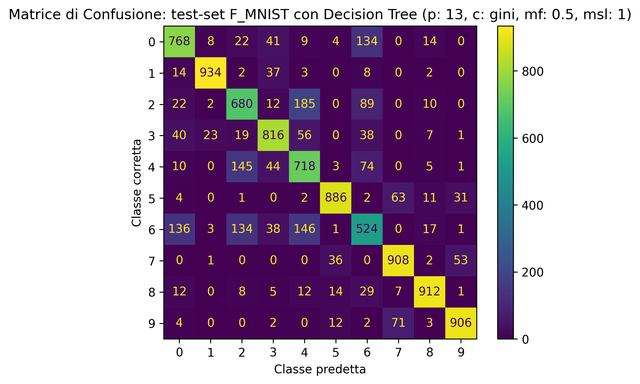
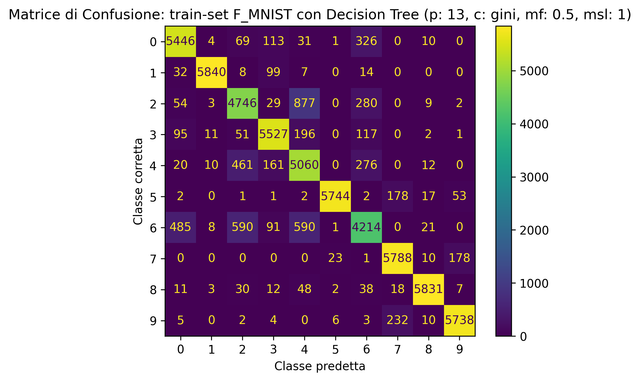
- [nome_classificatore]_classifier.py: Testa l'accuratezza del classificatore dopo aver settato manualmente i sui iper-parametri annotando nel file relativo allo storico dei test i risultati otenuti, la generazione automatica della matrice di confusione per individuare eventuale errori di classificazione e infine la generazione automatica dei 100 elementi classificati erroneamente;
[NB] Per un'ottima esperienza è bene eseguire lo script 1 e poi successivamente lo script 2, settando i parametri in base alle combinazioni ottenute dal primo script.
Qui di seguito vengono riportati due esempi di esecuzione uno per ogni tipologia di script
L'esempio prevede l'esecuzione dello script decisionTree_classifier_HO.py e decisionTree_classifier.py per un test del 27/10/2022 alle ore 12:52 sul set di dati F-MNIST.
Al termine dell'addestramento del modello si otterranno due nuove directory in images_output:
- images_output
- ... altri TEST
- Hyperparameter_Tuning_F_MNIST_DT_2022_10_27_12_52_16
- Accurancy_Graphic
- Accurancy_Graph.png
- Accurancy_Graphic
- TEST_F_MNIST_DT_2022_10_27_12_52_16
- Confusion_Matrix
- CM_test.png
- CM_train.png
- Erroneus_Classifications
- ...
- Errore_444.png
- ...
- Confusion_Matrix

Infine nei file di testo Test_History.txt e Test_History.txt sarà scritto il nuovo test effettuato con tutte le sue caratteristiche di seguito viene mostrato il formato:
DT su F_MNIST
Il tasso di accuratezza si aggirerà intorno al : 81.48%
| i | mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_criterion | param_max_depth | param_max_features | param_min_samples_leaf | ... |
|---|---|---|---|---|---|---|---|---|---|
| 33 | 15.865796 | 0.390363 | 0.102328 | 0.043465 | gini | 13 | 0.5 | 1 | ... |
| 69 | 15.163894 | 0.119052 | 0.109759 | 0.044534 | entropy | 11 | 0.5 | 1 | ... |
| 75 | 17.007989 | 0.223998 | 0.084056 | 0.026826 | entropy | 13 | 0.5 | 1 | ... |
| 73 | 28.103232 | 0.153905 | 0.080878 | 0.015820 | entropy | 13 | None | 25 | ... |
| 30 | 28.223590 | 0.221354 | 0.066648 | 0.004398 | gini | 13 | None | 1 | ... |
Migliori Iper-parametri: {'criterion': 'gini', 'max_depth': 13, 'max_features': 0.5, 'min_samples_leaf': 1}
-
Test del 2022-10-27 12:52:16 F_MNIST con Decision Tree (profondità: 13, c: gini, mf: 0.5, msl: 1):
- Tempo caricamento dataset: 0.457 sec
- Tempo addestramento modello: 15.118 sec
- TRAIN ACCURANCY: 89.89% LOG LOSS: 0.30497
- TEST ACCURANCY: 80.52% LOG LOSS: 2.44365
- TRAIN MSE: 1.126
- TEST MSE: 2.38
Report di classificazione
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.76 | 0.77 | 0.76 | 1000 |
| 1 | 0.96 | 0.93 | 0.95 | 1000 |
| 2 | 0.67 | 0.68 | 0.68 | 1000 |
| 3 | 0.82 | 0.82 | 0.82 | 1000 |
| 4 | 0.63 | 0.72 | 0.67 | 1000 |
| 5 | 0.93 | 0.89 | 0.91 | 1000 |
| 6 | 0.58 | 0.52 | 0.55 | 1000 |
| 7 | 0.87 | 0.91 | 0.89 | 1000 |
| 8 | 0.93 | 0.91 | 0.92 | 1000 |
| 9 | 0.91 | 0.91 | 0.91 | 1000 |
| accuracy | 0.81 | 10000 | ||
| macro avg | 0.81 | 0.81 | 0.81 | 10000 |
| weighted avg | 0.81 | 0.81 | 0.81 | 10000 |