基於Qwen-7B-Chat嘅微調版本,基於大量粵語數據進行訓練。
See also: huggingface & ModelScope
Star⭐ my project if u like it!
- Download Configs
git clone https://github.com/stvlynn/Qwen-7B-Chat-Cantonese
Download Release
cd Qwen-7B-Chat-Cantonese
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00001-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00002-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00003-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00004-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00005-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00006-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00007-of-00008.safetensors
wget --no-check-certificate --content-disposition https://github.com/stvlynn/Qwen-7B-Chat-Cantonese/releases/download/v1/model-00008-of-00008.safetensors
Pls turn to QwenLM/Qwen - Quickstart
| Parameter | Description | Value |
|---|---|---|
| Learning Rate | AdamW optimizer learning rate | 7e-5 |
| Weight Decay | Regularization strength | 0.8 |
| Gamma | Learning rate decay factor | 1.0 |
| Batch Size | Number of samples per batch | 1000 |
| Precision | Floating point precision | fp16 |
| Learning Policy | Learning rate adjustment policy | cosine |
| Warmup Steps | Initial steps without learning rate adjustment | 0 |
| Total Steps | Total training steps | 1024 |
| Gradient Accumulation Steps | Number of steps to accumulate gradients before updating | 8 |

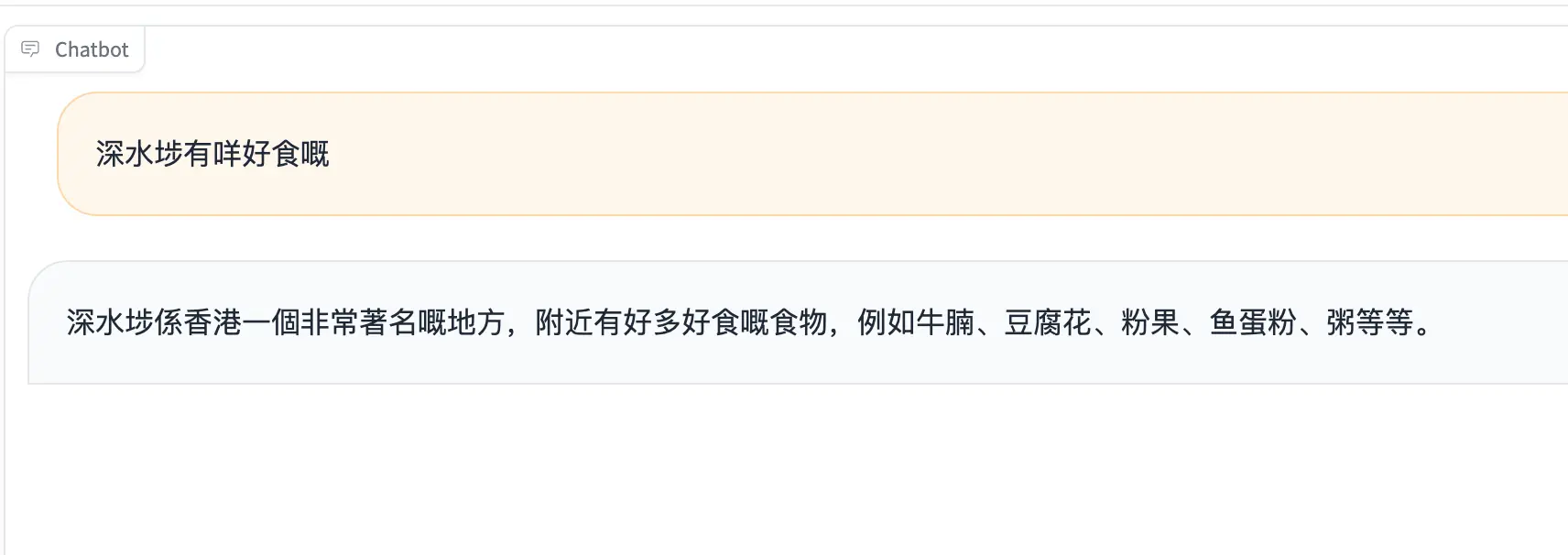
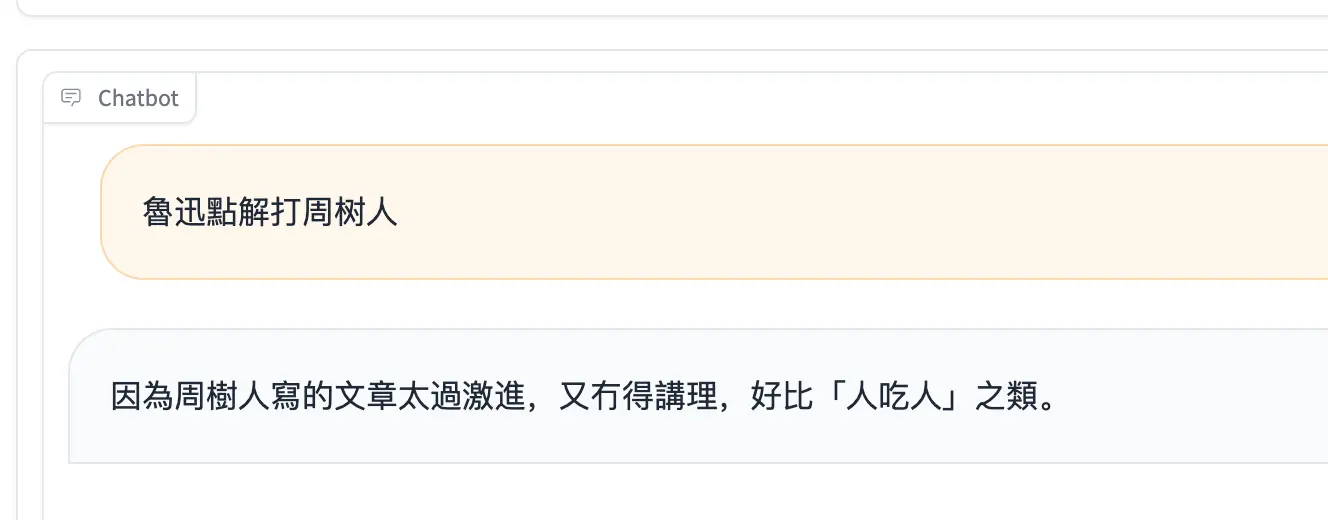
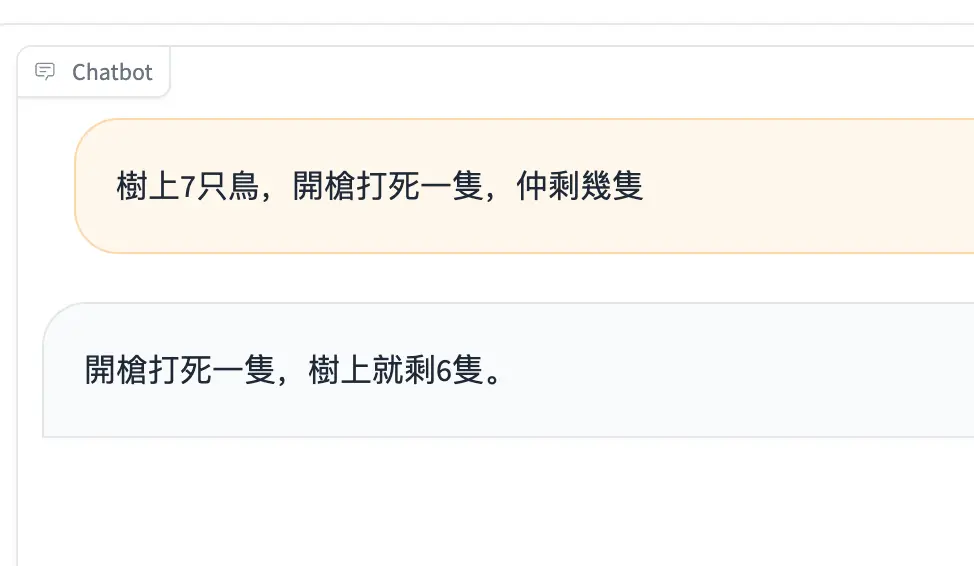
This is my first fine-tuning LLM project. Pls forgive me if there's anything wrong.
If you have any questions or suggestions, feel free to contact me.