Learn how to play the piano using this Alexa skill. With the Echo Show, it can play videos showing the individual keys to be played for songs on the piano.
For a demo of this skill, check out the entry in the DevPost Alexa Contest.

Architecture
Table of Contents
- How do you play a video within an Alexa skill?
- What are the video controls?
- How do you know if the request is coming from an Echo Show?
- How do you render a visual list of songs?
- Where are the songs cataloged?
- What event gets created when touching the Echo screen?
- How did you create the videos with keys labeled?
- How do you play audio files on any Alexa?
- How do you deploy changes to the skill from the command line?
Playing videos within the Echo show requires using the Video App Directives. Start by setting the Video App filed to yes on the Skill Information tab within the Developer Console. It should look like this.
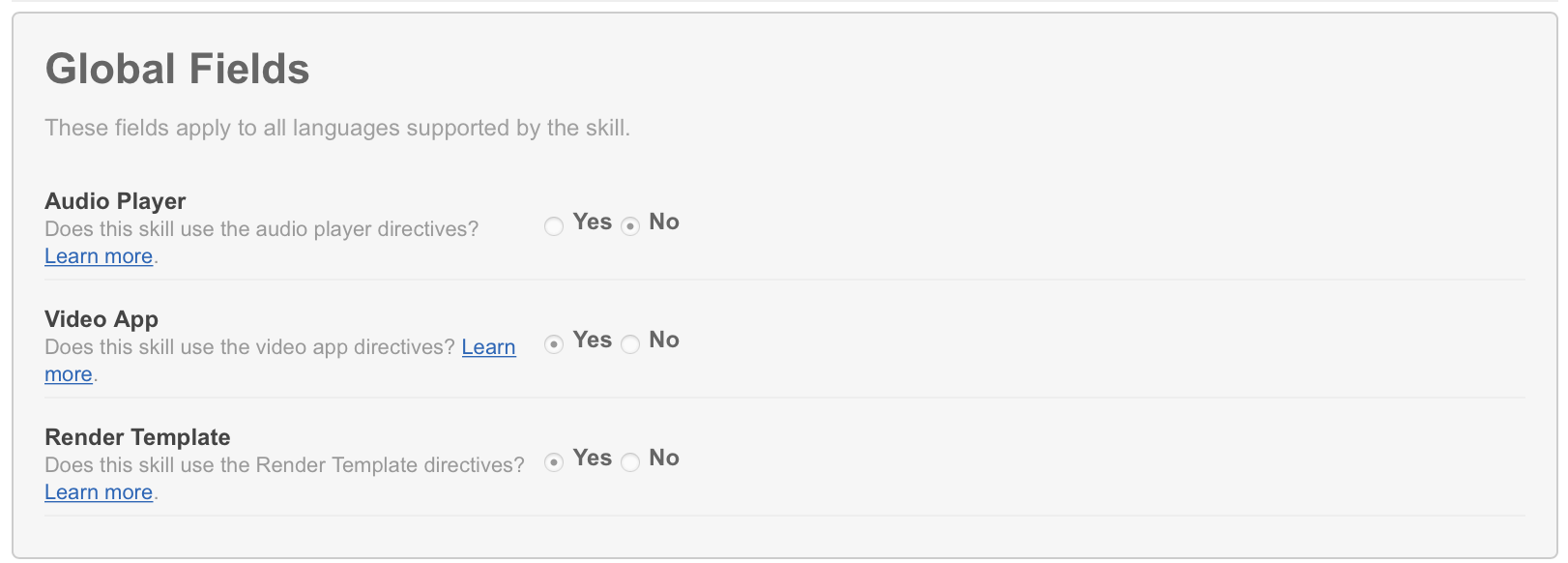
Then within the Lambda function, execute the following logic using the current NodeJS SDK.
# const videoClip = 'https://locationOfVideo.mp4'
this.response.playVideo(videoClip);Transfer then controls over to the video player, and then the user can control the video playback directly.
When playing a video, the user can pause, rewind, fast-forward, etc. on the video file that is being played. This can be done through voice commands, or by touching the Echo Screen. Please note: these commands do not require responses that invoke your skill. The device can handle them directly with the video file. This ensures a consistent user experience across skills, or the native video experience on the device. For more details on the Video App, here is the documentation from Amazon.
It's important to only play back videos to devices that have a screen. If a video file is passed back to a audio-only Alexa enabled device, the response will be marked in error, and the skill will terminate. For this skill, there is logic that leverages the ability of the Alexa SDK to detect if the device has a video player. Here is a sample of code that determines if one is present. The first line detects for a Video player enabled device.
// If the device is able to play video pass video, else audio
if (this.event.context.System.device.supportedInterfaces.VideoApp) {
const videoClip = videoLoc + 'DownScale.mp4';
const metadata = {
'title': 'Reverse Note Drill'
};
console.log("Invoked from video playing device");
this.response.playVideo(videoClip, metadata);
} else {
console.log("Playing from non-video device");
const audioMessage = 'Okay, get ready to play the scale in reverse starting with the ' +
'high C, then go up a white key until you hit the middle C.' +
'<break time="3s"/>' +
'<audio src=\"' + audioLoc + 'DownScale.mp3\" />' +
'<break time="3s"/>' +
'Would you like to play again? If so, say, Play the scale in reverse. ' +
'If you would are ready to play a song, say, List songs, then select one.';
const repeatMessage = 'If you want to try again, say, Play scale in reverse. ' +
'To play going back up, please say, Play the scale.';
this.response.speak(audioMessage).listen(repeatMessage);
}The video list comes from one of the visual templates, ListTemplate1. The data for all of the songs is stored in a local array, and for each. Here is the piece of code within the ListSongs function that builds the Template.
const itemImage = null; // note there is no image currently in the list
const listItemBuilder = new Alexa.templateBuilders.ListItemBuilder();
const listTemplateBuilder = new Alexa.templateBuilders.ListTemplate1Builder();
// build list of all available songs
for (i = 0; i < songs.length; i++ ) {
if (songs[i].listSong) {
// pull attributes from song array and apply to the list
listItemBuilder.addItem(null, songs[i].token, makePlainText(songs[i].requestName),
makePlainText(songs[i].difficulty));
message = message + songs[i].requestName + ", "
}
}
message = message + "Just select on the screen a song, or request by saying something " +
"like, Teach me how to play " + songs[0].requestName + ".";
const listItems = listItemBuilder.build();
const imageLoc = pianoStrings;
const listTemplate = listTemplateBuilder.setToken('listToken')
.setTitle('Available Song List')
.setListItems(listItems)
.setBackgroundImage(makeImage(imageLoc))
.build();
this.response.speak(message).listen(noSongRepeatMessage).renderTemplate(listTemplate);
this.emit(':responseReady');For reference, here is what the list object ends up looking like. The list does not currently have an image, but it does have both primary and secondary text.
{
"type": "ListTemplate1",
"token": "listToken",
"title": "Available Song List",
"listItems": [
{
"image": null,
"token": "song001",
"textContent": {
"primaryText": {
"text": "Silent Night",
"type": "PlainText"
},
"secondaryText": {
"text": "Moderate",
"type": "PlainText"
}
}
},
{
"image": null,
"token": "song002",
"textContent": {
"primaryText": {
"text": "Mary Had a Little Lamb",
"type": "PlainText"
},
"secondaryText": {
"text": "Easy",
"type": "PlainText"
}
}
},
...
],
"backgroundImage": {
"sources": [
{
"url": "https://s3.amazonaws.com/pianoplayerskill/logos/pianoStrings.jpg"
}
]
}
}Each item in the list also is identified with a unique token. This token is passed back to the skill if one of the songs of the list is selected by the touch screen on the Echo Show.
All of the current songs that this skill can play are stored in the songs.json file. This file is read into a local array, then referenced within various functions of the skill. There is a boolean named listSong that determines if the song name should be read during a listing of the skills. This is because there are duplicate entries in the array for multiple names that may be uttered by the user when trying to request a song.
Here is a sample of the data
[
{
"requestName": "Silent Night",
"listSong":true,
"token":"song001",
"difficulty":"Moderate",
"videoObject": "SilentNight.mp4",
"audioObject": "SilentNight.mp3"
},
{
"requestName": "Mary Had a Little Lamb",
"listSong":true,
"token":"song002",
"difficulty":"Easy",
"videoObject": "MaryHadLittleLamb.mp4",
"audioObject": "MaryHadLittleLamb.mp3"
},
...When a list template is used, the screen on the device has the ability to invoke the skill based on a touch event. This is the 'ElementSelected' event. The event passes in the token from the list under the attribute this.event.request.token. The function then matches the token value with the array of songs, and plays the video for the user. There is no audio equivalent to this feature as there is nothing to 'touch' on a standard Alexa device.
Much of the effort in building this skill was around creating the content for each song. We recorded the piano music we played using a mobile phone, as well as took pictures of the keys and other parts of the piano for use as backgrounds. Within Camtasia, there is a process of building layers of different items of media, then assembling. Here is a screenshot of Camtasia that highlights this.
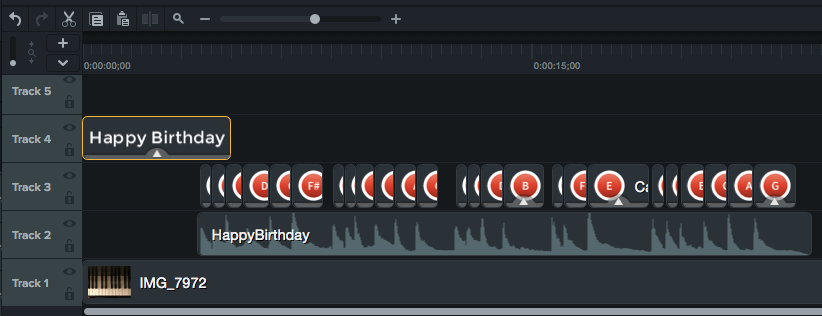
In making the videos, the base layer is a photograph(Track 1). By bringing in the audio from playing the piano (Track 2), we get a timeline that shows each note being played in the mp3 file. By the curve within the wave, we can tell when each note on the piano is struck, so we add another layer (Track 3) that highlights which note is being played. If there are multiple notes being played at once, then there are multiple images. Any titles at the beginning are another layer (Track 4).
When complete, Camtasia builds an mp4 file that is in a compatible format for playing on an Echo Show. We also create an mp3 file that can be used for non-video devices that use the skill. These are uploaded to an s3 bucket, and are made publicly available so they can be rendered by the Alexa device.
All Alexa devices have the ability to play back mp3 files in addition to the spoken word. This requires using SSML (Speech Synthesis Markup Language). For example, when playing the note recognition game, here is the attribute that plays a single chord.
const chordExample = 'https://s3.amazonaws.com/pianoplayerskill/musicChords/CMajorChord.mp3';
var message = 'A chord is a group of at least three notes that can be played ' +
'together and form the harmony. These are typically played with ' +
'your left hand while your right hand plays the melody. ' +
'An example is the Chord C Major. It is the C, E, and G notes played together ' +
'like this.' +
'<break time="1s"/>' +
'<audio src=\"' + chordExample + '\" />' +
'<break time="1s"/>' +
'These keys are pressed with your pinky, middle finger, and thumb. ' +
'If you would like to learn how to play a song, say List Songs to get started.';
this.emit(':ask', message, repromptChordMessage);
The markup syntax can mix both the natural voice of Alexa with mp3 files. Just include the endpoint of the mp3 file with the 'audio src' markup. An easy way to host audio files is through an s3 bucket. The markup can also add breaks up to ten seconds in length. That is through the 'break time' markup.
When developing this skill, I've used an IDE and a local copy of the GitHub repo. When I'm ready to test out the skill, I execute the build.sh script. This script has multiple steps.
- Create a local build package by zipping up the source code, songs.json file, and npm binaries.
- Stage the zipped file into a s3 bucket.
- Update the function code for the appropriate (Green/Blue) version of the skill. Which one depends on if I am updating the local test version or the one currently in production.
- Test the lambda function by invoking using locally managed test data.