
![]()
The Aerospace Corporation is proud to present our complex-valued encoder, decoder, and a new loss function for radio frequency (RF) digital signal processing (DSP) in PyTorch.
- via PyPI:
pip install glaucus - via source:
pip install .
pytestcoverage runpylint glaucus tests
The newest version of the autoencoder can encode arbitrary length continuous data using a combination of LSTM and residual vector quantization. Signal features are sequentially encoded and subtracted from the original, allowing a variable amount of compression from 51.2x to 819.2x.
import torch
from glaucus import GlaucusRVQVAE
# define model
model = GlaucusRVQVAE(quantize_dropout=True)
# get weights
state_dict = torch.hub.load_state_dict_from_url(
"https://github.com/the-aerospace-corporation/glaucus/releases/download/v2.0.0/gvq-1024-a4baf001.pth",
map_location="cpu",
)
model.load_state_dict(state_dict)
model.freeze()
model.eval()The model will take any (batch_size, length) as a complex tensor. The forward function will encode and decode sequentially returning the same shape as the input.
x_tensor = torch.randn(11, 11113, dtype=torch.complex64)
y_tensor = model(x_tensor) # shape (11, 11113)To get the compressed features from the input signal, you run the encode step. This returns a compressed feature tensor of (batch_size, input_len//compression_factor, num_quantizers) and a scale parameter. The decode function returns the reconstruction RMS normalized, or scaled if a scale parameter is given. compression_factor is equal to the product of the model compression_ratios and is 256 for the pretrained model.
x_tensor = torch.randn(3, 65536, dtype=torch.complex64)
y_encoded, y_scale = model.encode(x_tensor) # shapes ((3, 512, 16), (3,1))
y_tensor_rms = model.decode(y_encoded) # shape (3, 65536)
y_tensor = model.decode(y_encoded, y_scale) # shape (3, 65536)The pretrained model has a base compression of 51.2x, but can be scaled to 819.2x if desired by discarding N codebooks up to num_quantizers - 1. This will reduce reconstruction accuracy:
y_encoded_truncated = y_encoded[..., :9] # keep 9 of 16 codebooks; new shape (3, 512, 9)
y_tensor_57x = model.decode(y_encoded_truncated, y_scale) # shape (3, 65536)
y_tensor is an integer type, so to get the smallest binary representation for storage you can store the bytes. The y_tensor is only using log2(num_embed) bits, so if we are very clever we can pack bits to keep even fewer bytes. Compare sizes for the first item in the batch from above:
>>> from glaucus import pack_tensor, unpack_tensor
>>> len(x_tensor[0].numpy().tobytes())
524288
>>> len(pack_tensor(y_encoded[0].ravel())) # 51x smaller
10240
>>> len(pack_tensor(y_encoded_truncated[0].ravel())) # 91x smaller
5760
>>> recovered_y_encoded = unpack_tensor(pack_tensor(y_encoded[0].ravel())).reshape(1, -1, 16)
>>> model.decode(recovered_y_encoded).shape
torch.Size([1, 65536])The new vector quantization model accepts arbitrary length RF input and will utilize history between samples when reconstructing. This history does NOT extend between batches, e.g. for a (7, 8192) shape input the model will only have a "context length" of 8192.
If the input length is not a multiple of the the product of compression_ratios (256 for the current pretrained model), the model will output extra samples in the decoding step that you will need to truncate.
Variational Autoencoder with progressive resampling and a better defined latent space.
import torch
from glaucus import blockgen, GlaucusVAE
# define model
encoder_blocks = blockgen(steps=8, spatial_in=4096, spatial_out=16, filters_in=2, filters_out=64, mode="encoder")
decoder_blocks = blockgen(steps=8, spatial_in=16, spatial_out=4096, filters_in=64, filters_out=2, mode="decoder")
model = GlaucusVAE(encoder_blocks, decoder_blocks, bottleneck_in=1024, bottleneck_out=1024, data_format='nl')
# get weights
state_dict = torch.hub.load_state_dict_from_url(
'https://github.com/the-aerospace-corporation/glaucus/releases/download/v1.2.0/gvae-1920-2b2478a0.pth',
map_location='cpu')
model.load_state_dict(state_dict)
model.freeze()
model.eval()
# example usage
x_tensor = torch.randn(7, 4096, dtype=torch.complex64)
y_tensor, y_encoded, _, _ = model(x_tensor)Load quantized model and return compressed signal vector & reconstruction. Our weights were trained & evaluated on a corpus of 200 GB of RF waveforms with various added RF impairments for a 1 PB training set.
import sigmf
import torch
from glaucus import GlaucusAE
# create model
model = GlaucusAE(bottleneck_quantize=True, data_format='nl')
model = torch.quantization.prepare(model)
# get weights for quantized model
state_dict = torch.hub.load_state_dict_from_url(
'https://github.com/the-aerospace-corporation/glaucus/releases/download/v1.1.0/glaucus-512-3275-5517642b.pth',
map_location='cpu')
model.load_state_dict(state_dict, strict=False)
# prepare for prediction
model.freeze()
model.eval()
torch.quantization.convert(model, inplace=True)
# get samples into NL tensor
x_sigmf = sigmf.sigmffile.fromfile('example.sigmf')
x_tensor = torch.from_numpy(x_sigmf.read_samples())
# create prediction & quint8 signal vector
y_tensor, y_encoded = model(x_samples)
# get signal vector as uint8
y_encoded_uint8 = torch.int_repr(y_encoded)# define architecture
import torch
from glaucus import GlaucusAE, blockgen
encoder_blocks = blockgen(steps=6, spatial_in=4096, spatial_out=16, filters_in=2, filters_out=64, mode='encoder')
decoder_blocks = blockgen(steps=6, spatial_in=16, spatial_out=4096, filters_in=64, filters_out=2, mode='decoder')
# create model
model = GlaucusAE(encoder_blocks, decoder_blocks, bottleneck_in=1024, bottleneck_out=1024, bottleneck_quantize=True, data_format='nl')
model = torch.quantization.prepare(model)
# get weights for quantized model
state_dict = torch.hub.load_state_dict_from_url(
'https://github.com/the-aerospace-corporation/glaucus/releases/download/v1.1.0/glaucus-1024-761-c49063fd.pth',
map_location='cpu')
model.load_state_dict(state_dict, strict=False)
# see above for rest# create model, but skip quantization
from glaucus.utils import adapt_glaucus_quantized_weights
model = GlaucusAE(bottleneck_quantize=False, data_format='nl')
state_dict = torch.hub.load_state_dict_from_url(
'https://github.com/the-aerospace-corporation/glaucus/releases/download/v1.1.0/glaucus-512-3275-5517642b.pth',
map_location='cpu')
state_dict = adapt_glaucus_quantized_weights(state_dict)
# ignore "unexpected_keys" warning
model.load_state_dict(state_dict, strict=False)
# prepare for evaluation mode
model.freeze()
model.eval()
# see above for restimport np
import torch
import glaucus
# create criterion
loss = glaucus.RFLoss(spatial_size=128, data_format='nl')
# create some signal
xxx = torch.randn(128, dtype=torch.complex64)
# alter signal with 1% freq offset
yyy = xxx * np.exp(1j * 2 * np.pi * 0.01 * np.arange(128))
# return loss
loss(xxx, yyy)partial implementation:
import lightning as L
from glaucus import GlaucusAE
model = GlaucusAE(data_format='nl')
# this takes a very long time if no cache is available
signal_data = torchsig.datasets.Sig53(root=str(cache_path))
# 80 / 10 / 10 split
train_dataset, val_dataset, test_dataset = torch.utils.data.random_split(
signal_data,
(len(signal_data) * np.array([0.8, 0.1, 0.1])).astype(int),
generator=torch.Generator().manual_seed(0xCAB005E),
)
class RFDataModule(L.LightningDataModule):
'''
defines the dataloaders for train, val, test and uses datasets
'''
def __init__(self, train_dataset=None, val_dataset=None, test_dataset=None,
num_workers=16, batch_size=32):
super().__init__()
self.batch_size = batch_size
self.num_workers = num_workers
self.train_dataset = train_dataset
self.val_dataset = val_dataset
self.test_dataset = test_dataset
def train_dataloader(self):
return DataLoader(self.train_dataset, num_workers=self.num_workers, batch_size=self.batch_size, shuffle=True, pin_memory=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, num_workers=self.num_workers, batch_size=self.batch_size, shuffle=False, pin_memory=True)
def test_dataloader(self):
return DataLoader(self.test_dataset, num_workers=self.num_workers, batch_size=self.batch_size, shuffle=False, pin_memory=True)
datamodule = RFDataModule(
train_dataset=train_dataset,
val_dataset=val_dataset,
test_dataset=test_dataset,
batch_size=batch_size, num_workers=num_workers)
trainer = L.Trainer()
trainer.fit(model, datamodule=datamodule)
# test with best checkpoint
trainer.test(model, datamodule=datamodule, ckpt_path="best")| model weights | desc | published | mem (MB) | params (M) | multiadds (M) | provenance |
|---|---|---|---|---|---|---|
| gvq-1024-a4baf001.pth | VQ-VAE | 2024-09-11 | 60.3 | 14.655 | 2370 | .016 pfs-days on general waveform Aerospace Dset |
| gvae-1920-2b2478a0.pth | VAE | 2024-03-25 | 21.6 | 3.440 | 263 | .006 pfs-days on general waveform Dset. |
| glaucus-1024-sig53TLe37-2956bcb6 | AE for Sig53 | 2023-05-16 | 19.9 | 2.873 | 380 | transfer learning from glaucus-1024-761-c49063fd w/Sig53 Dset |
| glaucus-1024-761-c49063fd | AE accurate | 2023-03-02 | 19.9 | 2.873 | 380 | .035 pfs-days modulation & general waveform Aerospace Dset |
| glaucus-512-3275-5517642b | AE small | 2023-03-02 | 17.9 | 2.030 | 259 | .009 pfs-days on modulation-only Aerospace Dset |
Per OpenAI appendix here is the correct math (method 1):
pfs_days= (add-multiplies per forward pass) * (2 FLOPs/add-multiply) * (3 for forward and backward pass) * (number of examples in dataset) * (number of epochs) / (flop per petaflop) / (seconds per day)- (number of examples in dataset) * (number of epochs) = steps * batchsize
- 1
pfs-day≈ (8x V100 GPUs at 100% efficiency for 1 day) ≈ (100x GTX1080s at 100% efficiency for 1 day) ≈ (35x GTX 2080s at 100% efficiency for 1 day) ≈ 500 kWh
Code prior to v2.0.0 is documented by the two following IEEE publications.
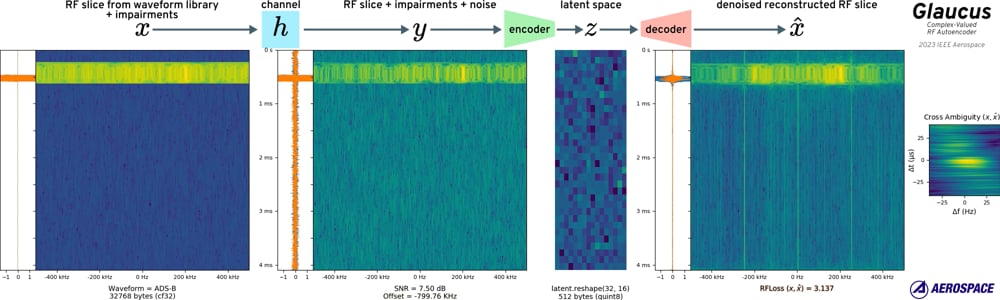
A complex-valued autoencoder neural network capable of compressing & denoising radio frequency (RF) signals with arbitrary model scaling is proposed. Complex-valued time samples received with various impairments are decoded into an embedding vector, then encoded back into complex-valued time samples. The embedding and the related latent space allow search, comparison, and clustering of signals. Traditional signal processing tasks like specific emitter identification, geolocation, or ambiguity estimation can utilize multiple compressed embeddings simultaneously. This paper demonstrates an autoencoder implementation capable of 64x compression hardened against RF channel impairments. The autoencoder allows separate or compound scaling of network depth, width, and resolution to target both embedded and data center deployment with differing resources. The common building block is inspired by the Fused Inverted Residual Block (Fused-MBConv), popularized by EfficientNetV2 & MobileNetV3, with kernel sizes more appropriate for time-series signal processing
A new optimized loss for training complex-valued neural networks that require reconstruction of radio signals is proposed. Given a complex-valued time series this method incorporates loss from spectrograms with multiple aspect ratios, cross-correlation loss, and loss from amplitude envelopes in the time & frequency domains. When training a neural network an optimizer will observe batch loss and backpropagate this value through the network to determine how to update the model parameters. The proposed loss is robust to typical radio impairments and co-channel interference that would explode a naive mean-square-error approach. This robust loss enables higher quality steps along the loss surface which enables training of models specifically designed for impaired radio input. Loss vs channel impairment is shown in comparison to mean-squared error for an ensemble of common channel effects.
Do you have code you would like to contribute to this Aerospace project?
We are excited to work with you. We are able to accept small changes immediately and require a Contributor License Agreement (CLA) for larger changesets. Generally documentation and other minor changes less than 10 lines do not require a CLA. The Aerospace Corporation CLA is based on the well-known Harmony Agreements CLA created by Canonical, and protects the rights of The Aerospace Corporation, our customers, and you as the contributor. You can find our CLA here.
Please complete the CLA and send us the executed copy. Once a CLA is on file we can accept pull requests on GitHub or GitLab. If you have any questions, please e-mail us at oss@aero.org.
The Aerospace Corporation supports Free & Open Source Software and we publish our work with GPL-compatible licenses. If the license attached to the project is not suitable for your needs, our projects are also available under an alternative license. An alternative license can allow you to create proprietary applications around Aerospace products without being required to meet the obligations of the GPL. To inquire about an alternative license, please get in touch with us at oss@aero.org.