Tianyi Wang
2019 Dec 15th
This project is a pipeline to clean and tokenize messages sent during disaster events, fit machine learning model (random forest classifier) on the messages and their categories (so the model can classify new messages), and present the analysis on the data and a small message classification application on a website. This project is one of Udacity Data Scientist Nanodegree projects.
The machine learning pipeline is based on data like this:
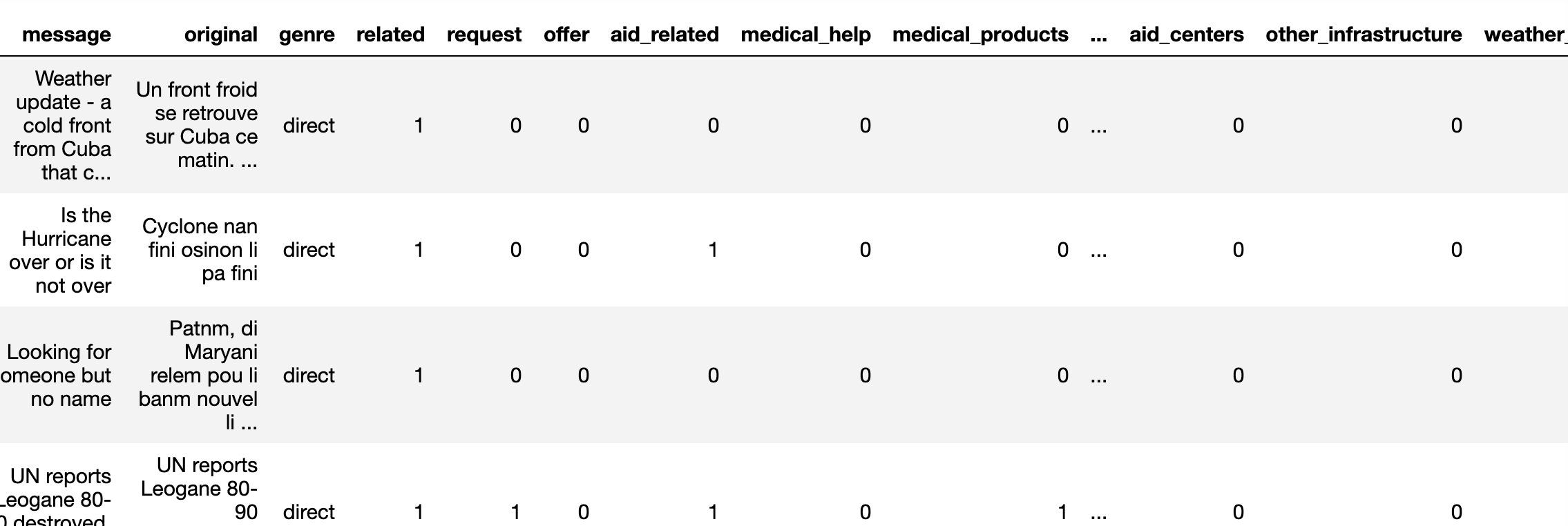
Every message sent may belong to one or more categories. There are many categories:
Messages and categories are stored in different files. We first combined these two tables and did some data cleaning and stored the table to a sqlite database. Then we used MultiOutputClassifier and RandomForestClassifier in sklearn to fit the messages and categories data.
When tuning the model, we used grid search method on a variety of parameters including min_samples_split, min_samples_leaf and max_features. To handle the data imblanace (some categories have much fewer training samples), we used f1_score as the scoing function and we actually saw that model with higher f1 score also has higher accuracy. After we finished grid searching and got the fitted model, we stored the model as a pickle file.
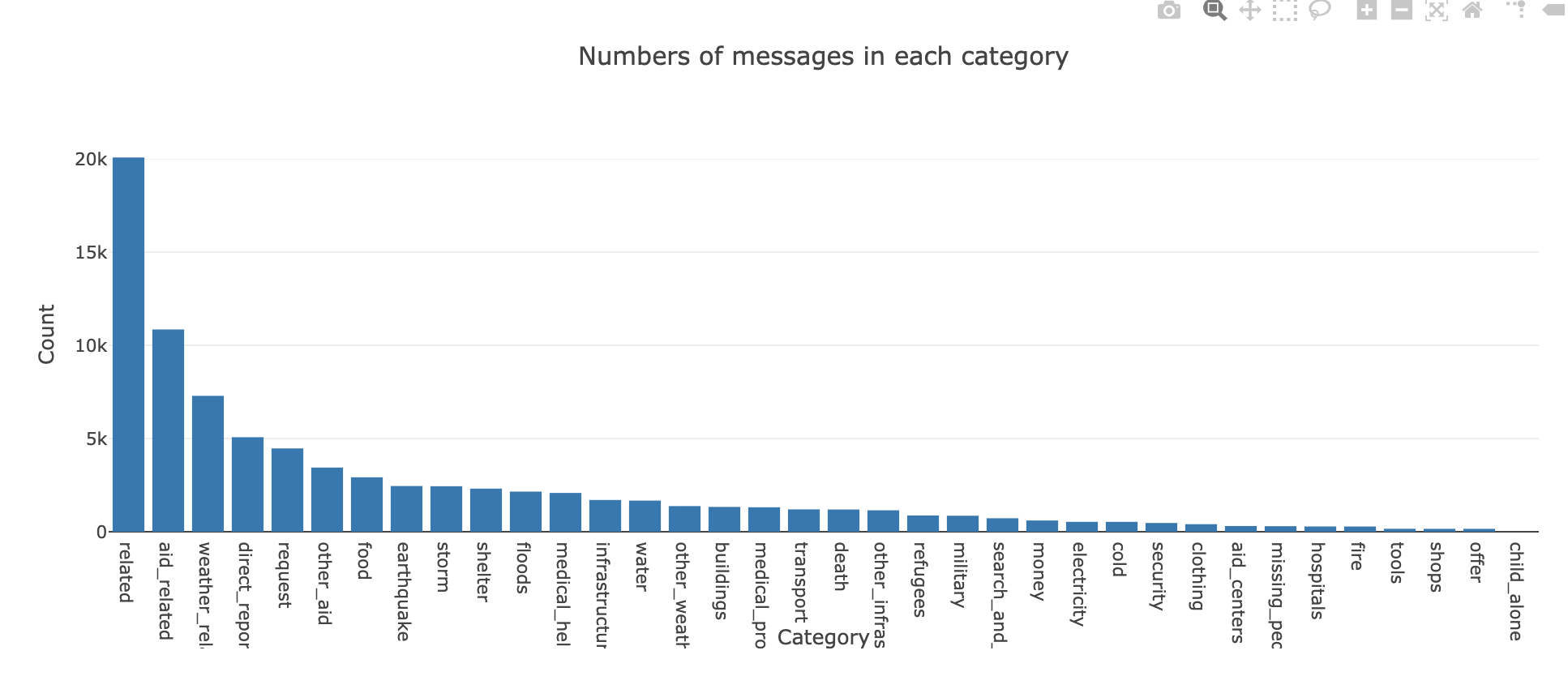
The output of the analysis will be fed to the Disaster Response Project web app template. On the homepage we will display some visualizations to present an overview of the training dataset:
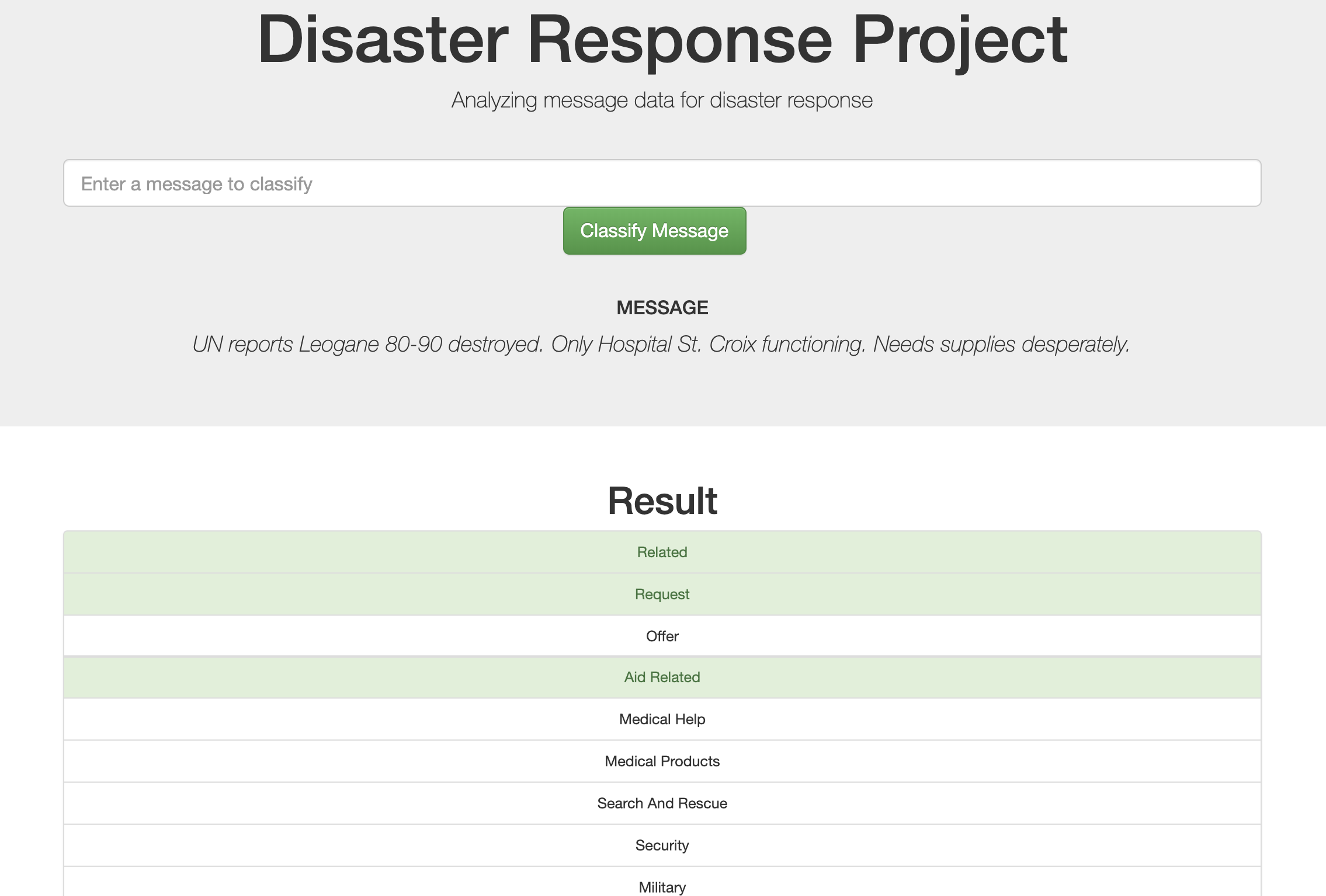
You can enter a message to classify:
- data: folder where the messages and categories data are stored
- templates: html templates of the web app
- message_classification.db: sqllite_database where the combined table of the messages and categories sits
- model: we have trained the model (test average f1 scores among categories is 0.2612; test average accuracy: 95.86%) so you can directly run the web app; but you can definitely retrain the model yourself
- run.py: scipts for running the web app
- train_classifier.py: script for fitting machine learning models and saving the best model
- process_data: scripts for ETL pipeline and load the data into sqlite database
To run the ETL pipeline and save the cleaned data to sqlite database, run process_data.py in the terminal:
$ python process_data.pyYou can specify the following optional variables:
- messages_file_path: file path of the message data
- categories_file_path: file path of the categories data
- table_name: name of the combined table; default: "message_table"
- database_file_path: file path of the sqlite database
To retrain the model, you can run train_classifier.py in the terminal
$ python train_classifier.pyYou can actually specify a lot of variables
- table_name: name of the combined table; default: "message_table"
- database_file_path: file path of the sqlite database
- gridsearch_params: grid search parameters; defalt:
"{'clf__estimator__min_samples_split': [5, 10, 15], 'clf__estimator__min_samples_leaf': [1, 3, 5]}"; You should pass in the dictionary in a string, the algorithm will convert it todict - n_folds: numbers of cross validation folds; default: 5
- n_jobs: number of jobs to run in parallel; default: 1
To run the app, you can run run.py in the terminal
$ python run.pyThe web app will be hosted on http://0.0.0.0:3002/
If you specified a different table_name when you run train_model.py, you will also need to specify it here
$ python run.py --table_name <your_table_name>