中文说明
Weibo is one of the most influential social networking sites in China, with a huge number of Chinese users. Its function is similar to Twitter, and when I crawled, I even found that Weibo programmers also followed some variable names of twitter (kinda ashamed..hehe). Therefore, if you don't understand Chinese, you can just look at the model design of this repository without checking the crawled content (tweets,tweets topics and so on).
Performing sentiment analysis can classify users into various categories and push corresponding advertisements to them. The sentiment analysis I chose to do was to divide users into real users and bots. According to most of the papers on Weibo bots detection, the method they use is to classify users through logistic regression on various metrics (follow count, fans count, average tweet time, etc.) of users. I think that the accuracy of such method is not high, and unstable for different test sets. This kind of task requires the help of the NLP model, because the biggest difference between the bot and the real person is the behavior and habits of how they write tweets.
The program and the training and testing process behind the program
Input
│── User information metrics:[follow_count, followers_count, interact_count, VIP_rank, VIP_type, tweets_count, weibo_lvl, is_verified, verified_type]
│── The latest 1 st tweet
│ │── Content
│ │── Tweet topic ("topic" is an attribute of a tweet in Weibo, it can be null if the user doesn't write any topic)
│ │── Retweeted content's feature:[topic,included_video?,included_pics?] or "Not including Retweet"
│ └── Tweet information metrics:[pics_count,video_play_count,retweets_count,comments_count,likes_count]
│── The latest 2 nd tweet
│── The latest ... th tweet
│── The latest n-1 th tweet
└── The latest n th tweet
Output
│── is real user
└── is bot
In my opinion, it is not enough to analyze a user with just one random tweet. We need to analyze continuous tweets from a single user. That is, performing sentiment analysis (I used Bi-LSTM model) to each n tweets parallelly, and then put these n outputs (try to treat them as tokens of a sentence) into a network, finally get the classification. And humans have a habit of writting. For example, some people post happy content every 3 days and then post a serious content, and some people may post sad content every day. Let's say John's lastest 8 tweets will be [happy, happy, happy, SERIOUS, happy, happy, happy, SERIOUS], so we know he will have 2 serious tweets out of every 8 tweets. Although [SERIOUS, SERIOUS, happy, happy, happy, happy, happy, happy] has the same frequency of two types of tweets, but due to the different order, the "shape" of sequence is different, and we cannot say that this is John's habit of writting. [happy, happy, SERIOUS, happy, happy, happy, SERIOUS, happy] is just the sequence shifted one unit to the left (actually, it doesn’t matter how much it shifts), but it has the same "shape", so we can say this is John's habit of writing. Therefore, the network used to connect n outputs will also be an recurrent model (I also used LSTM again). Since this is a nested parallel LSTM model, in order to prevent the gradient from disappearing, most of the activation functions I use are Tanh, and 40%-dropout is performed on some layers to prevent overfitting. Below is the structure of the model.
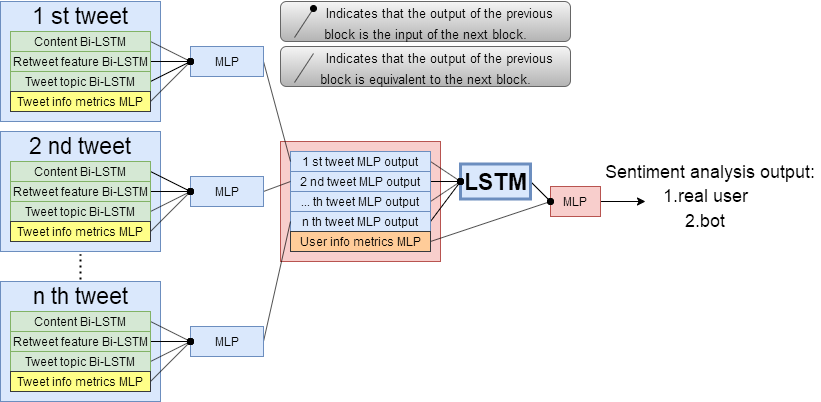
I have a user_id data set of 568 samples(274 bots and 294 real users). All samples are manually inspected to ensure the logic and distribution of the data set as much as possible, thereby objectively ensuring the fairness of test set accuracy.
Input the user_id data set to my crawler, then it will output the new dataset (as I described above, "The structure of model input") for the model. At the same time, {Content} and {Tweet topic; Retweeted content's feature} have very different grammar, vocabulary and sentence length. Therefore, when embedding, I created their own dictionaries for them, which can also lead to a lower input dimension of one-hot encoding of {Tweet topic; Retweeted content's feature}。
| Training set split rate | Test set accuracy | n tweets | baseline file |
|---|---|---|---|
| 85% | 98.84% | 20 | weibo_baselines |
| 50% | 90.14% | 20 | |
| 15% | 90.48% | 20 |
The 20-tweet data set dictionary has 27890 tokens. There are different dictionaries for each different training set. For example, the dictionary has 25000 tokens when the training set is 85% of the data set. It has 10000 tokens when it is 15%. Howevery, all the test sets' accuracy is still above 90% even if there are so many unknown tokens(words) in the test sets.