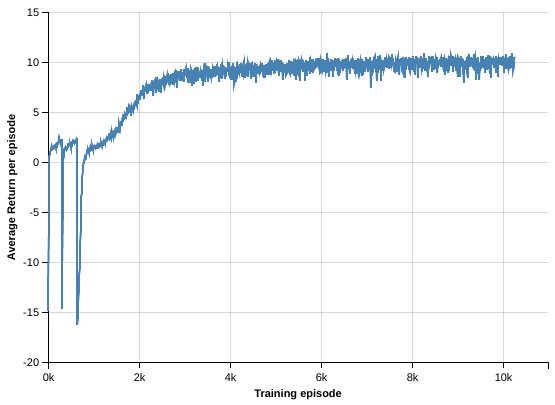We approached the challenge mainly from the classic reinforcement learning with function approximation setting as we were more interested in building models capable of learning complex policies and determining the behaviour of other agents rather than developing hard-coded heuristics informed by human experience.
In order to acquire an understanding of the task at hand and the dynamics of the Malmo-Challenge world we experimented with various deep reinforcement learning methods, starting with well known value-based algorithms and arriving at a variation of the Advantage Asynchronous Actor-Critic with recurrent units and augmented with two auxiliary cost functions used to help our learning algorithm internalize the episodic behaviour of the Challenger Agent.
To speed up the experimentation cycle we built a secondary environment approximating the dynamics of the Malmo-Challenge task in the top-view mode. We further successfully used this medium for transfer learning experiments as detailed below. We performed all the experiments on the top-view symbolic view as we deemed it a good computational trade-off while still representing a sufficient statistics for our reinforcement learning algorithms.
Early experimentation involved training feed-forward parametrized estimators with DQN, Double DQN (in order to compensate for over-estimation effects early in the training) and policy-gradient based methods. We concluded policy-gradient based methods with recurrent units could provide us with a good baseline to build upon. For this purpose we implemented a state of the art Advantage Actor-Critic inspired by Mnih2016 with a four layer convolutional neural network for feature extraction fed into two successive GRU layers. Next are two fully connected layers and the final softmax, value, and auxiliary reward heads. The state representation we used during training was a 18x9x9 tensor, with three layers for sand, grass and lapis blocks and five layers for each of the two agents and the pig, encoding their position and orientation. We provide code for all the models discussed in this overview.
Auxiliary tasks
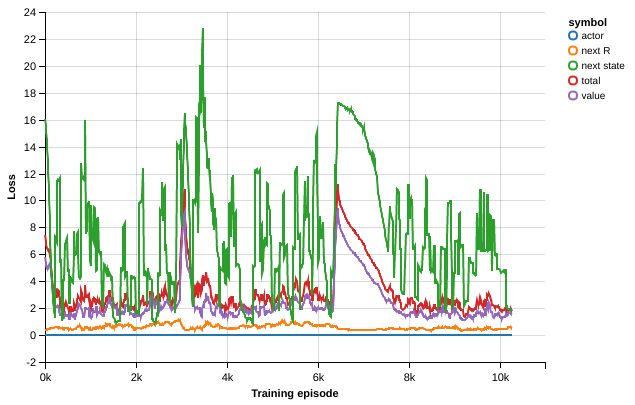
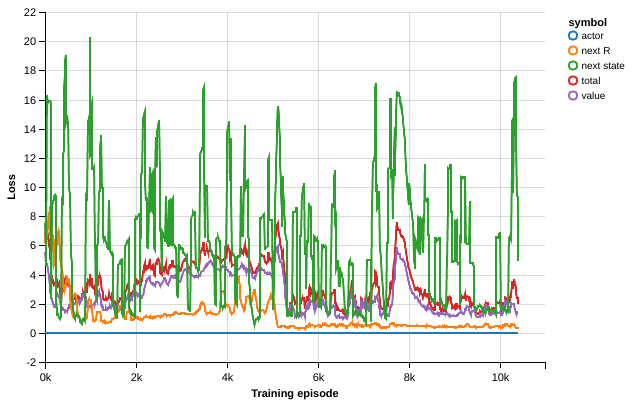
While the recurrent A3C model was able to learn a good policy with good sample-efficiency we tried to provide our model with additional cost functions designed to help learning relevant features for the present task as first developed in Jaderberg2016.
Specifically we trained the agent on predicting the instantaneous reward at the next step in order for our model to learn faster about states and situations leading to high reward.
The second auxiliary task we trained with was next map prediction. We first considered fully generating the next map, complete with the future position of the Challenger Agent and the Pig, hoping that this would help our agent determine the unknown policy of the Challenger Agent based on its moves. We first considered feeding the hidden states of the recurrent layers into a deconvolution for generating the next state of the map, however we observed a severe slow-down during learning when training this way. Therefore we set up to predict a random coordinate on the (18, 9, 9) state representation we used for our agents. At the start of each episode we picked a random coordinate to be predicted at each time-step. We hypothesize this additional cost function helps our agent to learn faster the dynamics of the environment and the given policy of the Challenger Agent during each episode.
Training
We employed a two-stage training process as follows:
-
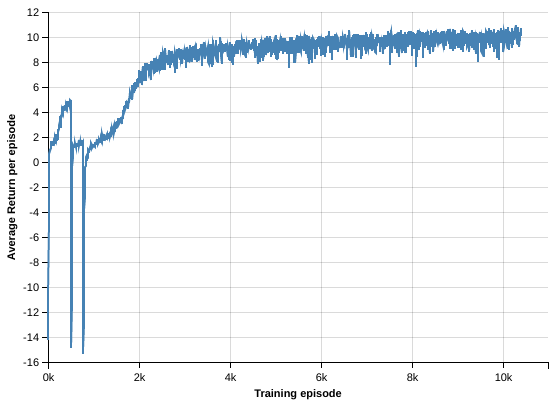
Pre-training on the secondary environment. As mentioned above we developed a secondary environment that approximates the dynamics of the Malmo-Challenge world in the top-down view. We used this environment to generate large batches of 1024 variable length episodes, doing an optimization step on each batch using RMSProp. We used batch normalization between the convolutional layers as we noticed it improves the sample-complexity of our model and allows for higher learning rates. This initial pre-training phase allowed us easy quick experimentation with various models and, more importantly, a good prior when training our model on the Malmo-Challenge. A main difference from A3C is that we didn't use an asynchronous set-up but we leveraged the ability of our environment to serve large batches of episodes.
-
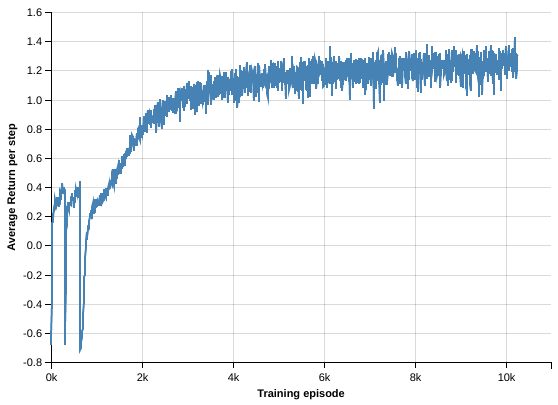
Training on the Malmo-Challenge environment. We used the full pre-trained model and a custom StateBuilder to further train our agent on the Malmo-Challenge environment. For this phase we started multiple environments and employed a training scheme inspired by GA3C Babaeizadeh2017, collecting prediction requests from all the workers and doing batched prediction on a single model. A separate training process is doing optimization steps on batches of 128 episodes. We noticed best results in this phase using Adam optimisation with a smaller-learning rate.
We also considered a hierarchical model learning at different time resolutions inspired by FeUdal Networks Vezhnevets2017, reasoning the Malmo-Challenge set-up is a good example of learning different skills or options (exiting the pigsty and collaborating to catch the Pig) while also taking higher-level decisions about which of the learned options to follow depending on the policy of the Challenge Agent. Although it is a research direction we plan to pursue further, the preliminary results on the Malmo-Challenge suggest less involved methods based on policy-gradient methods are perfectly capable of solving the task.
You can evaluate our trained model with: python test_challenge.py