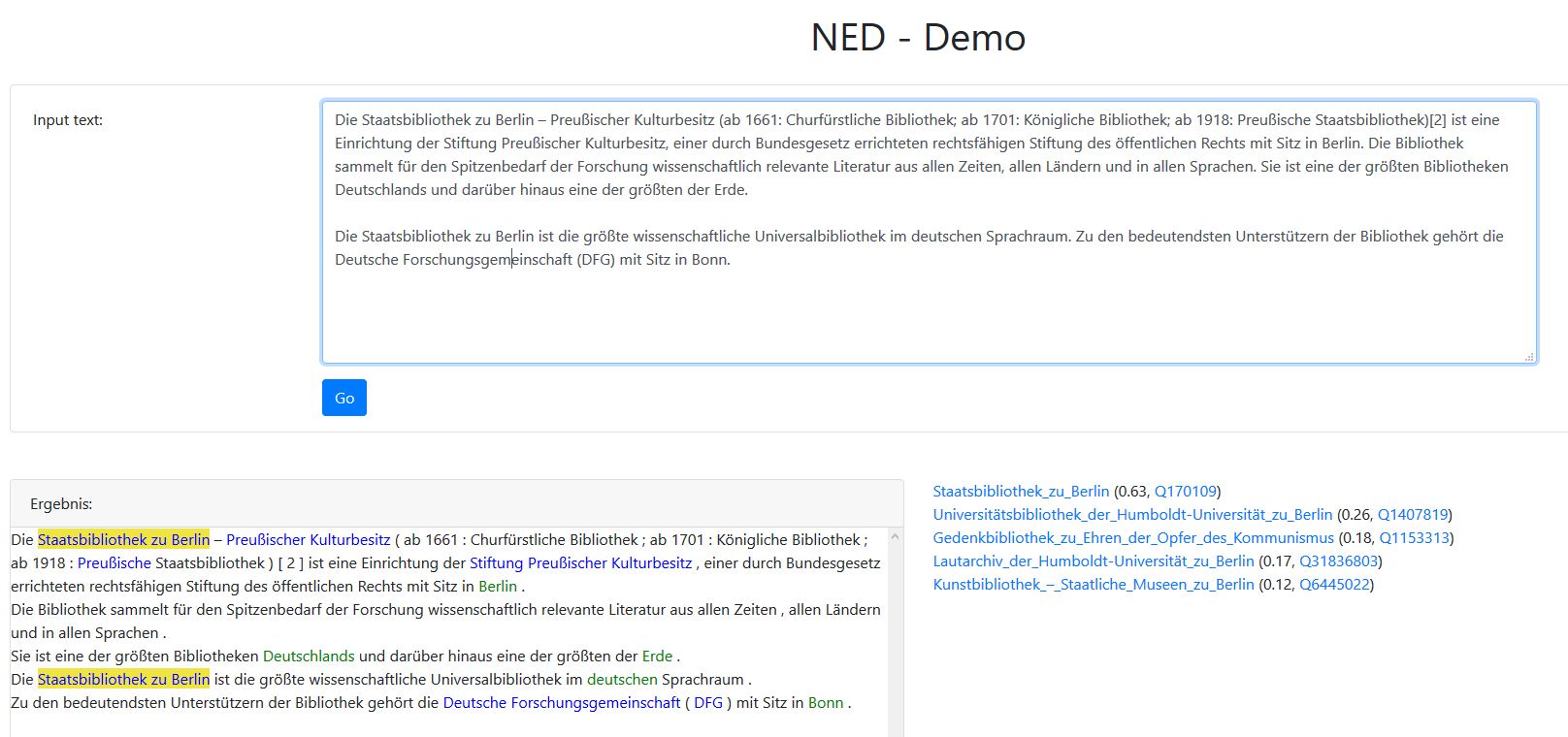
An overview of the functionality of the NED system can be found in our CLEF 2020 HIPE paper. Based on the CLEF 2020 observations, we improved the system and performed a new evaluation in the CLEF 2022 HIPE Entity Linking task. Currently there is also a demo-installation online.
Before named entity disambiguation (NED) can be performed, the input text has to be NER-tagged. Our NED system provides a HTTP-interface that accepts the NER-tagged input in JSON format.
In order to try our NED-system, you can either use some NER-tagger and convert the output of that system into the expected format, or you can download and install the SBB-NER-tagger and use the output of that system as input of our NED-system.
Please consider the example section at the bottom or read the installation guide of the SBB-NER-tagger for more detailed information about the expected input format of the NED-system.
If you want to use the NED - demo web interface as it is shown in the image above, you have to
- install and run the SBB-NER-tagger
- install and run the SBB-NED system
- setup an nginx installation (or other HTTP proxy) such that the NER and the NED system are available behind a URL-structure as it is defined by the nginx configuration example below:
server {
listen 80 default_server;
server_name _;
client_max_body_size 2048M;
location /sbb-tools/ner/ {
proxy_pass http://localhost:5000/;
proxy_connect_timeout 360000s;
proxy_send_timeout 360000s;
proxy_read_timeout 360000s;
send_timeout 360000s;
}
location /sbb-tools/ned/ {
proxy_pass http://localhost:5001/;
proxy_connect_timeout 360000s;
proxy_send_timeout 360000s;
proxy_read_timeout 360000s;
send_timeout 360000s;
}
}
NED web-interface is availabe at http://localhost/sbb-tools/ned/index.html .
NED as it is done by our system is computationally demanding, therefore computations in particular for larger documents can take a long time. Therefore the nginx configuration contains very high timeout settings for proxy connections since otherwise the connection could break before the result of the computation has been submitted.
Note: If there is another proxy in between, the connection can break due to timeouts within that proxy! HTTP obviously is not made to perform single requests of long durations, therefore we recommend to split up processing of larger documents in smaller requests which is possible due to the design of our system. However, for academic purposes it sometimes is more convenient to do large requests where the computation might take several hours.
Clone this project, the SBB-NER-tagger and the SBB-utils.
Setup virtual environment:
virtualenv --python=python3.6 venv
Activate virtual environment:
source venv/bin/activate
Upgrade pip:
pip install -U pip
Install packages together with their dependencies in development mode:
pip install -e sbb_utils
pip install -e sbb_ner
pip install -e sbb_ned
Download required models: https://qurator-data.de/sbb_ned/models.tar.gz (content of archive)
Beware: The archive file contains the required models as well as the knowledge bases for german, french and english, altogether roughly 200GB!!!
Change into NED directory:
cd sbb_ned
Extract model archive:
tar -xzf models.tar.gz
Run webapp directly:
env CONFIG=de-config.json env FLASK_APP=qurator/sbb_ned/webapp/app.py env FLASK_ENV=development env USE_CUDA=True flask run --host=0.0.0.0 --port=5001
Replace de-config.json by fr-config.json or en-config.json to switch to french or english. Set USE_CUDA=False, if you do not have a GPU available/installed (This NED already takes some time with GPU, it might not be feasible without GPU).
Perform NER (This works only if you install and run the SBB-NER-tagger:
curl --noproxy '*' -d '{ "text": "Paris Hilton wohnt im Hilton Paris in Paris." }' -H "Content-Type: application/json" http://localhost/sbb-tools/ner/ner/0
Answer:
[[{'prediction': 'B-PER', 'word': 'Paris'},
{'prediction': 'I-PER', 'word': 'Hilton'},
{'prediction': 'O', 'word': 'wohnt'},
{'prediction': 'O', 'word': 'im'},
{'prediction': 'B-ORG', 'word': 'Hilton'},
{'prediction': 'I-ORG', 'word': 'Paris'},
{'prediction': 'O', 'word': 'in'},
{'prediction': 'B-LOC', 'word': 'Paris'},
{'prediction': 'O', 'word': '.'}]]
Reorder NER result:
curl --noproxy '*' -d '[[{"prediction":"B-PER","word":"Paris"},{"prediction":"I-PER","word":"Hilton"},{"prediction":"O","word":"wohnt"},{"prediction":"O","word":"im"},{"prediction":"B-ORG","word":"Hilton"},{"prediction":"I-ORG","word":"Paris"},{"prediction":"O","word":"in"},{"prediction":"B-LOC","word":"Paris"},{"prediction":"O","word":"."}]]' -H "Content-Type: application/json" http://localhost/sbb-tools/ned/parse
HINT: In order to test the system without proxy in between you can use http://localhost:5001/parse as request url instead:
curl --noproxy '*' -d '[[{"prediction":"B-PER","word":"Paris"},{"prediction":"I-PER","word":"Hilton"},{"prediction":"O","word":"wohnt"},{"prediction":"O","word":"im"},{"prediction":"B-ORG","word":"Hilton"},{"prediction":"I-ORG","word":"Paris"},{"prediction":"O","word":"in"},{"prediction":"B-LOC","word":"Paris"},{"prediction":"O","word":"."}]]' -H "Content-Type: application/json" http://localhost:5001/parse
Answer:
{'Hilton Paris-ORG': {'sentences': [{'entities': '["Paris Hilton-PER", "Paris '
'Hilton-PER", "-", "-", '
'"Hilton Paris-ORG", "Hilton '
'Paris-ORG", "-", '
'"Paris-LOC", "-"]',
'tags': '["B-PER", "I-PER", "O", "O", '
'"B-ORG", "I-ORG", "O", "B-LOC", '
'"O"]',
'target': 'Hilton Paris-ORG',
'text': '["Paris", "Hilton", "wohnt", '
'"im", "Hilton", "Paris", "in", '
'"Paris", "."]'}],
'surfaces': ['hilton paris', 'Hilton Paris'],
'type': 'ORG'},
'Paris Hilton-PER': {'sentences': [{'entities': '["Paris Hilton-PER", "Paris '
'Hilton-PER", "-", "-", '
'"Hilton Paris-ORG", "Hilton '
'Paris-ORG", "-", '
'"Paris-LOC", "-"]',
'tags': '["B-PER", "I-PER", "O", "O", '
'"B-ORG", "I-ORG", "O", "B-LOC", '
'"O"]',
'target': 'Paris Hilton-PER',
'text': '["Paris", "Hilton", "wohnt", '
'"im", "Hilton", "Paris", "in", '
'"Paris", "."]'}],
'surfaces': ['paris hilton', 'Paris Hilton'],
'type': 'PER'},
'Paris-LOC': {'sentences': [{'entities': '["Paris Hilton-PER", "Paris '
'Hilton-PER", "-", "-", "Hilton '
'Paris-ORG", "Hilton Paris-ORG", '
'"-", "Paris-LOC", "-"]',
'tags': '["B-PER", "I-PER", "O", "O", "B-ORG", '
'"I-ORG", "O", "B-LOC", "O"]',
'target': 'Paris-LOC',
'text': '["Paris", "Hilton", "wohnt", "im", '
'"Hilton", "Paris", "in", "Paris", '
'"."]'}],
'surfaces': ['paris', 'Paris'],
'type': 'LOC'}}
Perform NED/NEL on re-ordered NER-result:
curl --noproxy '*' -d '{"Hilton Paris-ORG":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Hilton Paris-ORG","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["hilton paris","Hilton Paris"],"type":"ORG"},"Paris Hilton-PER":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Paris Hilton-PER","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["paris hilton","Paris Hilton"],"type":"PER"},"Paris-LOC":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Paris-LOC","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["paris","Paris"],"type":"LOC"}}' -H "Content-Type: application/json" http://localhost/sbb-tools/ned/ned
HINT: In order to use the system without proxy in between you can use http://localhost:5001/ned as request url instead:
curl --noproxy '*' -d '{"Hilton Paris-ORG":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Hilton Paris-ORG","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["hilton paris","Hilton Paris"],"type":"ORG"},"Paris Hilton-PER":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Paris Hilton-PER","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["paris hilton","Paris Hilton"],"type":"PER"},"Paris-LOC":{"sentences":[{"entities":"[\"Paris Hilton-PER\", \"Paris Hilton-PER\", \"-\", \"-\", \"Hilton Paris-ORG\", \"Hilton Paris-ORG\", \"-\", \"Paris-LOC\", \"-\"]","tags":"[\"B-PER\", \"I-PER\", \"O\", \"O\", \"B-ORG\", \"I-ORG\", \"O\", \"B-LOC\", \"O\"]","target":"Paris-LOC","text":"[\"Paris\", \"Hilton\", \"wohnt\", \"im\", \"Hilton\", \"Paris\", \"in\", \"Paris\", \".\"]"}],"surfaces":["paris","Paris"],"type":"LOC"}}' -H "Content-Type: application/json" http://localhost:5001/ned
Answer:
{'Hilton Paris-ORG': {'ranking': [['Hilton_Worldwide',
{'proba_1': 0.46, 'wikidata': 'Q1057464'}],
['Hôtel_de_Paris',
{'proba_1': 0.19, 'wikidata': 'Q1279896'}]]},
'Paris Hilton-PER': {'ranking': [['Paris_Hilton',
{'proba_1': 0.96, 'wikidata': 'Q47899'}]]},
'Paris-LOC': {'ranking': [['Paris_(New_York)',
{'proba_1': 0.15, 'wikidata': 'Q538772'}]]}}
Look into the relevant section of the Knowledge-base README.
For entire processing chain look into the Makefile.
build-index --help
Usage: build-index [OPTIONS] ALL_ENTITIES_FILE [fasttext|bert] ENTITY_TYPE
N_TREES OUTPUT_PATH
Create an approximative nearest neightbour index, based on the surface
strings of entities that enables a fast lookup of NE-candidates.
ALL_ENTITIES_FILE: Pandas DataFrame pickle that contains all entites.
EMBEDDING_TYPE: Type of embedding [ fasttext, bert ]
ENTITY_TYPE: Type of entities, for instance ORG, LOC, PER ...
N_TREES: Number of trees in the approximative nearest neighbour index
OUTPUT_PATH: Where to write the result files.
Options:
--n-processes INTEGER Number of parallel processes. default: 6.
--distance-measure [angular|euclidean]
default: angular
--split-parts Process entity surfaces in parts.
--model-path PATH From where to load the embedding model.
--layers TEXT Which layers to use. default -1,-2,-3,-4
--pooling TEXT How to pool the output for different
tokens/words. default: first.
--scalar-mix Use scalar mix of layers.
--max-iter INTEGER Perform only max-iter iterations (for
testing purposes). default: process
everything.
For entire processing chain look into the Makefile.
ned-sentence-data --help
Usage: ned-sentence-data [OPTIONS] TAGGED_SQLITE_FILE NED_SQLITE_FILE
TAGGED_SQLITE_FILE: A sqlite database file that contains all wikipedia
articles where the relevant entities have been tagged. This is a database
that gives per article access to the tagged sentences, it can be created
using 'tag-wiki-entities2sqlite'.
NED_SQLITE_FILE: Output database. This database gives fast per entity and
per sentence access, i.e., it provides a fast answer to the question:
"Give me all sentences where entity X is discussed."
Options:
--processes INTEGER number of parallel processes. default: 6
--writequeue INTEGER size of database write queue. default: 1000.
--help Show this message and exit.
ned-train-test-split --help
Usage: ned-train-test-split [OPTIONS] NED_SQL_FILE TRAIN_SET_FILE
TEST_SET_FILE
Splits the sentence data into train and test set.
NED_SQL_FILE: See ned-sentence-data.
Output:
TRAIN_SET_FILE: Pickled pandas DataFrame that contains the sentence ids of
the training set.
TEST_SET_FILE: Pickled pandas DataFrame that contains the sentence ids of
the test set.
Options:
--fraction-train FLOAT fraction of training data.
--help Show this message and exit.
ned-bert --help
Usage: ned-bert [OPTIONS] BERT_MODEL OUTPUT_DIR
bert_model: Bert pre-trained model selected in the list:
bert-base-uncased, bert-large-uncased, bert-base-cased,
bert-large-cased, bert-base-multilingual-uncased,
bert-base-multilingual-cased, bert-base-chinese.
output_dir: The output directory where the model predictions
and checkpoints will be written.
Options:
--model-file PATH Continue to train on this model file.
--train-set-file PATH See ned-train-test-split.
--dev-set-file PATH See ned-train-test-split.
--test-set-file PATH See ned-train-test-split.
--train-size INTEGER
--dev-size INTEGER
--train-size INTEGER
--cache-dir PATH Where do you want to store the pre-trained
models downloaded from s3
--max-seq-length INTEGER The maximum total input sequence length
after WordPiece tokenization. Sequences
longer than this will be truncated, and
sequences shorter than this will be
padded.
--do-lower-case Set this flag if you are using an uncased
model.
--train-batch-size INTEGER Total batch size for training.
--eval-batch-size INTEGER Total batch size for eval.
--learning-rate FLOAT The initial learning rate for Adam.
--weight-decay FLOAT Weight decay for Adam.
--num-train-epochs FLOAT Total number of training epochs to
perform/evaluate.
--warmup-proportion FLOAT Proportion of training to perform linear
learning rate warmup for. E.g., 0.1 = 10%%
of training.
--no-cuda Whether not to use CUDA when available
--dry-run Test mode.
--local-rank INTEGER local_rank for distributed training on gpus
--seed INTEGER random seed for initialization
--gradient-accumulation-steps INTEGER
Number of updates steps to accumulate before
performing a backward/update pass. default:
1
--fp16 Whether to use 16-bit float precision
instead of 32-bit
--loss-scale FLOAT Loss scaling to improve fp16 numeric
stability. Only used when fp16 set to True.
0 (default value): dynamic loss scaling.
Positive power of 2: static loss scaling
value.
--ned-sql-file PATH See ned-sentence-data
--embedding-type [fasttext]
--embedding-model PATH
--n-trees INTEGER
--distance-measure [angular|euclidean]
--entity-index-path PATH
--entities-file PATH
--help Show this message and exit.