Tinymind Neural Networks
Neural networks within tinymind are implemented using C++ templates and cusomtized via template parameters, both types as well as policy classes. Since the code is implemented using C++ templates, this allows us to instantiate neural networks within a very small code and data footprint. You only compile what you need and do not have to lug around a huge runtime library which contains a bunch of code you may never use. You can define a very specific set of neural network(s) for a very specific set of type(s) and that's all you pay for.
template<
typename ValueType,
size_t NumberOfInputs,
size_t NumberOfHiddenLayers,
size_t NumberOfNeuronsInHiddenLayers,
size_t NumberOfOutputs,
typename TransferFunctionsPolicy,
bool IsTrainable = true,
size_t BatchSize = 1,
bool HasRecurrentLayer = false,
hiddenLayerConfiguration_e HiddenLayerConfig = NonRecurrentHiddenLayerConfig,
size_t RecurrentConnectionDepth = 0,
outputLayerConfiguration_e OutputLayerConfiguration = FeedForwardOutputLayerConfiguration
>
class MultilayerPerceptron
{
...
ValueType - The underlying value type used by the neural network. It could be: int, float, or some other user-defined type like a QValue type. Any type will work as long as it supports the required operators.
NumberOfInputs - Number of input neurons in the neural network.
NumberOfHiddenLayers - Number of neural network hidden layers.
NumberOfNeuronsInHiddenLayers - Number of neurons in the hidden layers. At this time all hidden layers must have the same number of neurons.
NumberOfOutputs - Number of output neurons in the neural network.
TransferFunctionsPolicy - Policy class which provides certain functionality the neural network needs: Random number generation, initial weight values, neural network activation functions, etc.
IsTrainable - Compile time flag to indicate whether or not the neural network is trainable. Non-trainable neural networks consume less space as code and data required for trainable neural networks is not compiled into the binary image. Tinymind neural networks can have their weights, biases, etc. loaded from the outside world so that non-trainable neural networks can have their values initialized to trained ones. Training neural networks offline and instantiating untrainable neural networks within the embedded device can save a lot of code and data space.
BatchSize - Batch size for trainable neural networks who want to accumulate a BatchSize amount of samples before back-propagating the error thru the network.
HasRecurrentLayer - Compile time flag which configures the neural network's hidden as either purely feed-forward or recurrent.
HiddenLayerConfig - Hidden layer configuration parameter to choose between: Feed-forward, simple recurrent, GRU, or LSTM hidden layer type.
RecurrentConnectionDepth - Recurrent connection depth(i.e. number of backwards time steps to save in the recurrent layer).
OutputLayerConfiguration - Output layer configuration which configures the neural network's output layer as either feed forward or classifier type.
The parent class for all tinymind neural networks is MultilayerPerceptron. This class is configured via the template parameters to have the desired behavior. Some instances of the template parameters are instantiated within the class, while others are simple used by the class via static function calls. A simple class diagram of MultilayerPerceptron and its relationship to others is presented below.

When the neural network is initialized, it has to configure itself by calling upon its TransferFunctionsPolicy. From its TransferFunctionsPolicy it gets initial weight values, initial learning rate, etc.
 Tinymind does not assume anything about the environment within which the neural network is instantiated. This is why it relies upon the presence of a policy class, TransferFunctionsPolicy. This makes the code more portable in that is does assume the presence of random number generation hardware. It also does not initialize the network itself. It relies upon the policy class to handle that in any way it desires.
Tinymind does not assume anything about the environment within which the neural network is instantiated. This is why it relies upon the presence of a policy class, TransferFunctionsPolicy. This makes the code more portable in that is does assume the presence of random number generation hardware. It also does not initialize the network itself. It relies upon the policy class to handle that in any way it desires.
The simple training flow thru a feed-forward neural network is documented here.
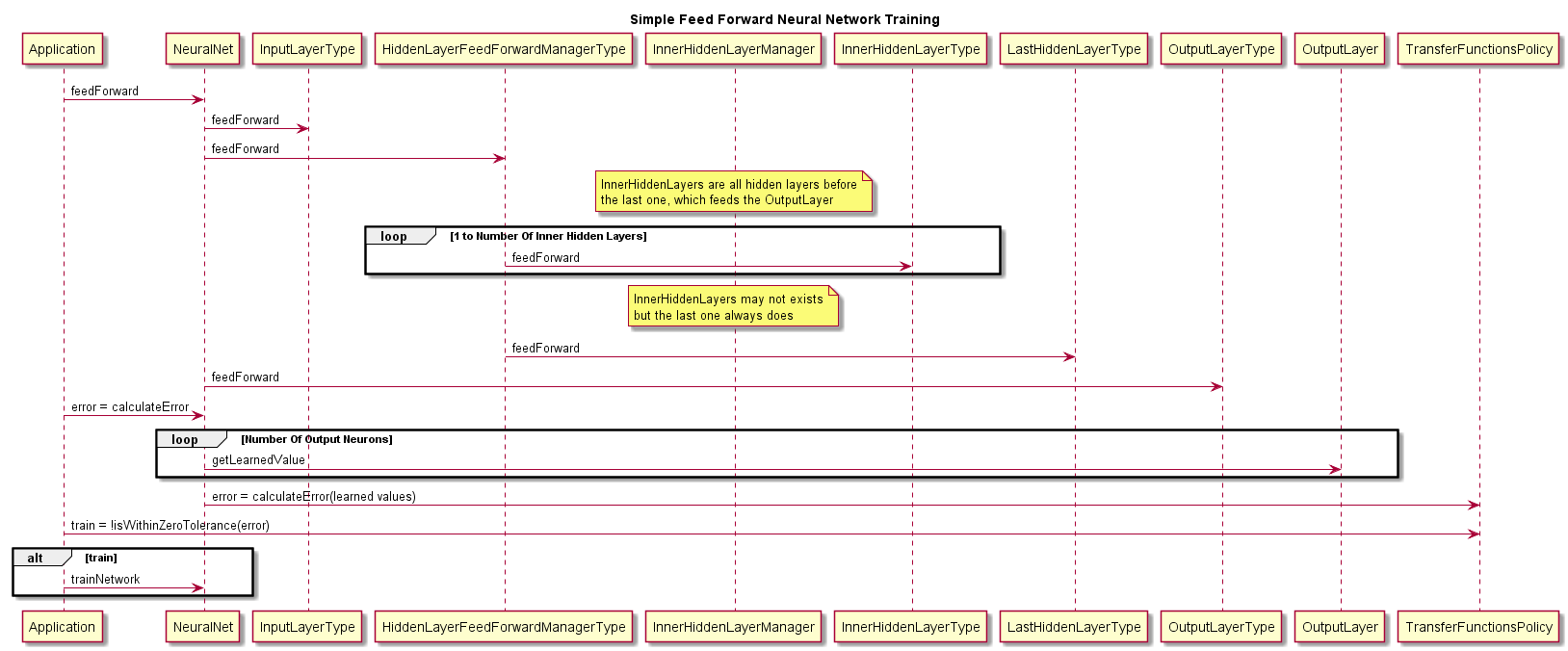 In the feed-forward pass, inputs are fed into the neural network. The neural network calculates the predicted output values and stores them in the OutputLayer. When
In the feed-forward pass, inputs are fed into the neural network. The neural network calculates the predicted output values and stores them in the OutputLayer. When calculateError is called, the error between the predicted output and the actual output fed into the neural network is returned to the caller. If the delta between the neural network calculated outputs and known outputs is too large, the creator of the neural network can call the trainNetwork API to force the neural network to back-propagate the calculated error thru the network layers and update the connection weights to try and minimize this error on the next invocation.